- 인터넷은 우리에게 자유를 주었습니다. 저희는 자유를 얻기 위해 지식을 통합하고 체계화하고 공유합니다. 랜선 위 정글에서 살아남기 위해 저희는 시키는 일만 하는 꿀벌 대신 고객을 위해 창조하고 혁신하는 게릴라가 되겠습니다. Seenbuy.kr is now Aiforu.kr.
- 024042463
- 01032667931
- [email protected]
얀덱스 웹마스터 도구( https://webmaster.yandex.com/ )

얀덱스의 검색엔진으로서의 지위( https://www.yandex.com )
얀덱스는 러시아에서 60%의 시장 점유율을 차지하는 러시아 최대의 검색 엔진을 운영하는 인터넷 기업입니다. 또, 수많은 인터넷 기반 서비스와 제품들을 개발하고 있습니다. 컴스코어에 따르면 얀덱스는 전 세계 검색 엔진에서 4위입니다. 얀덱스에 관한 보다 자세한 내용은 /yandex-seo-or-optimization-beyond-google/ 을 참조하세요.
얀덱스 웹마스터 도구( https://webmaster.yandex.com/ )
얀덱스 웹마스터 도구는 얀덱스를 위한 훌륭한 검색엔진최적화(SEO) 도구입니다.
전세계 4위에 검색엔진에 잘 노출되도록 최적화하는 도구가 얀덱스 웹마스터 도구입니다. 구글의 서치 콘솔에 해당합니다. 이 사이트에 사이트 등록 및 소유권 확인을 하게 되면 얀덱스에 노출되게 되며 양질의 백링크를 얻을 수 있습니다.
다국어 사이트를 구축한 경우이거나 번역 기능을 제공하는 사이트인 경우, 꼭 활용해야할 도구입니다.
얀덱스 웹마스터 도구는 훌륭한 구글의 검색엔진최적화(SEO) 도구이기도 합니다.
아래의 이미지는 구글 서치 콘솔의 [링크] 보고서를 캡처한 이미지입니다. [상위 링크 사이트]를 클릭하시면
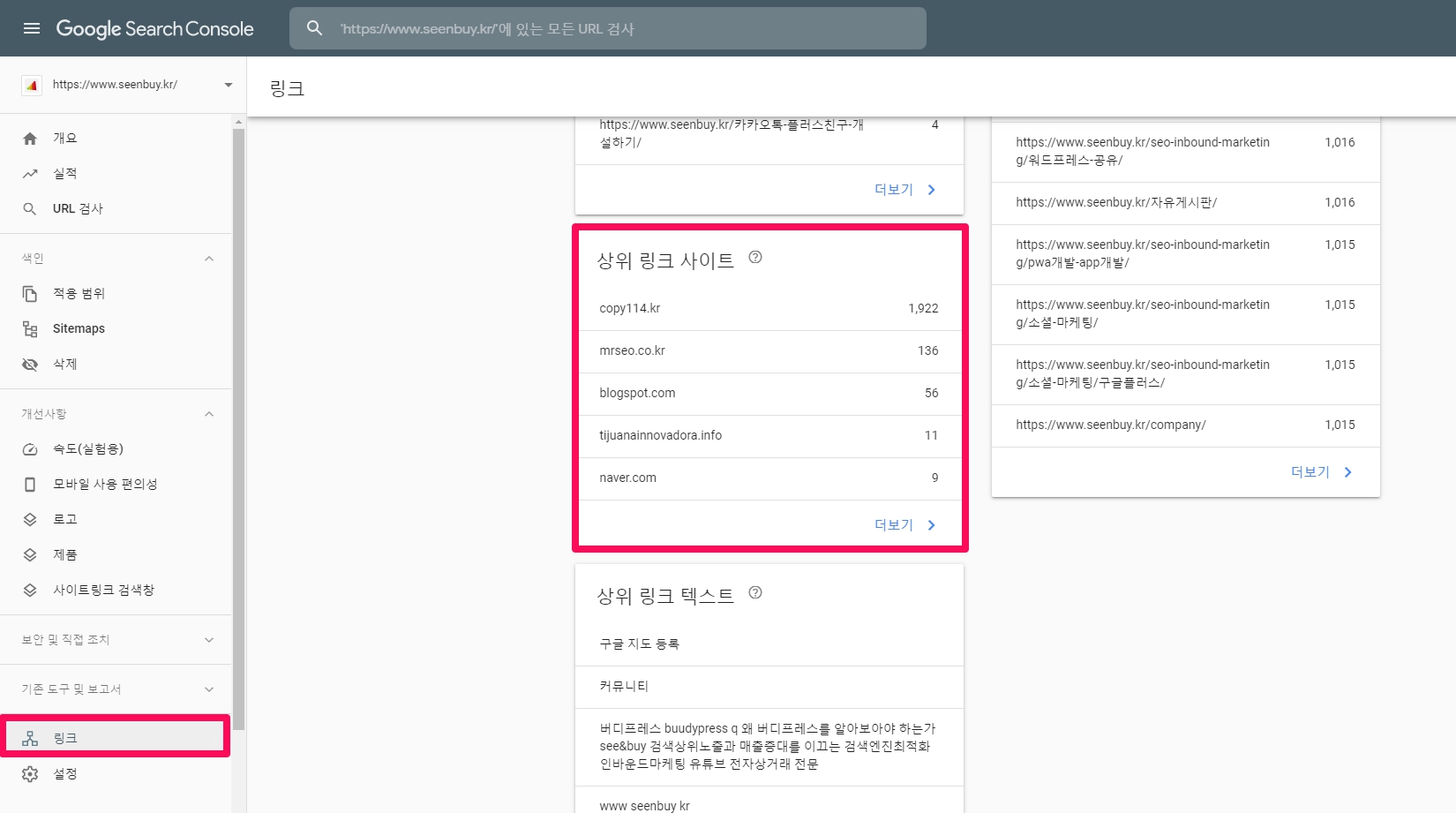
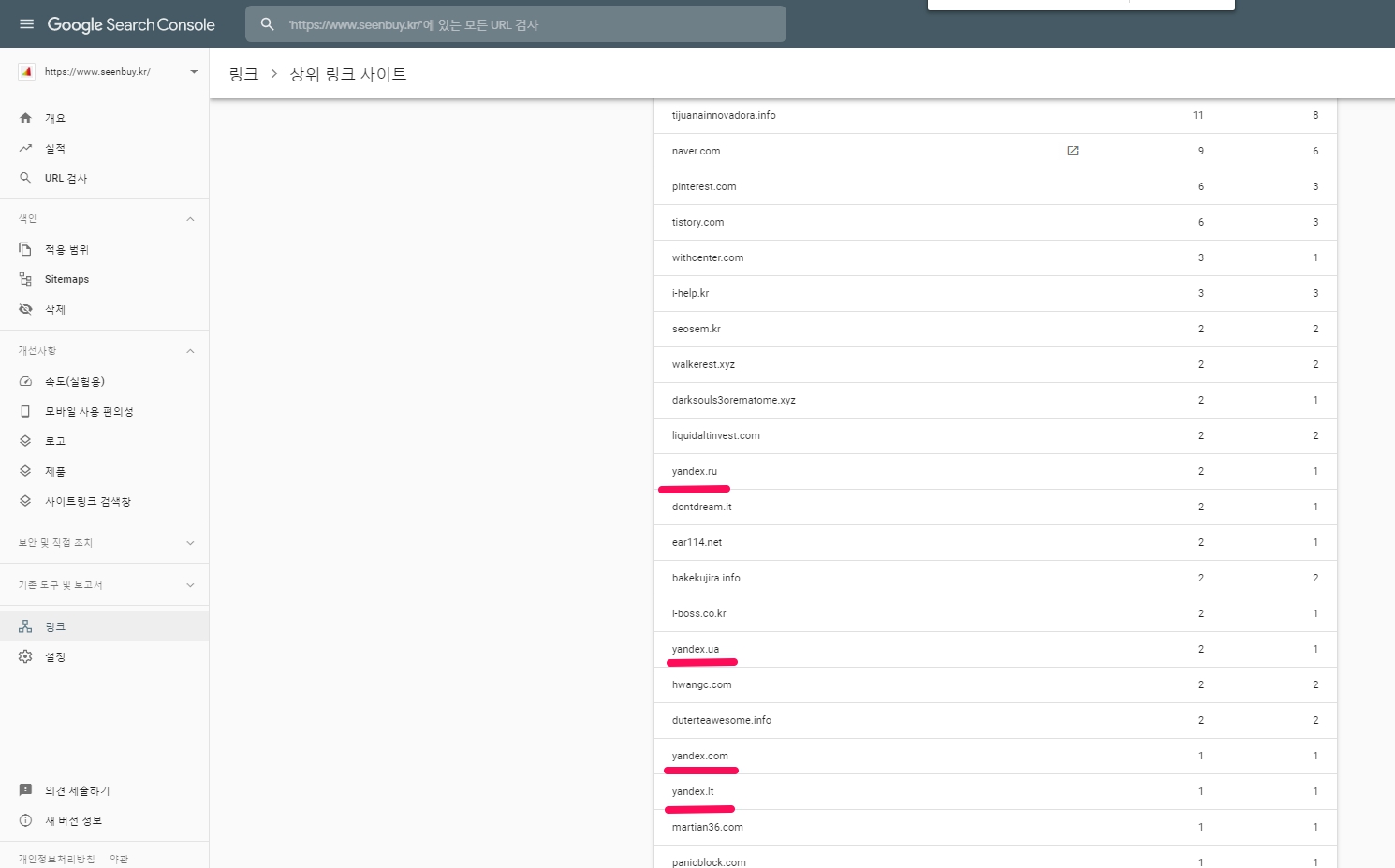
상위 링크된 사이트들의 상세 내역이 나오는데, yandex.ru, yandex.ua, yandex.com, yandex.lt 등이 보입니다. https://www.prchecker.info/ 를 통해 구글 페이지 랭크를 확인하실 수 있는데, 각각의 검색엔진의 구글 페이지 랭크는 yandex.ru는 8/10, yandex.ua는 6/10, yandex.com는 7/10입니다. yandex.lt는 순위가 제공되지 않고 있습니다. 이처럼 높은 페이지 랭크를 가진 포털 사이트로부터 얻는 링크는 일반 웹사이트로부터 얻는 링크와는 비교할 수 없는 양질의 링크이며 다양성 또한 얻을 수 있다는 점에서 높은 검색결과 순위 요소임입니다.
(참고로, 네이버의 구글 페이지 랭크는 8/10입니다. .ru는 1994년 4월 7일 도입된 러시아 연방의 국가 코드 최상위 도메인입니다. .ua는 우크라이나의 국가 코드 최상위 도메인입니다.. .lt는 리투아니아의 인터넷 국가 코드 최상위 도메인입니다. )
얀덱스 웹마스터 도구( https://webmaster.yandex.com/ ) 활용법
Yandex Webmaster로 이동한후 처음 사용하시는 분들은 가입( Registration ) 부터 한후 로그인합니다.
영어라 부담없이 가입( Registration )할 수 있고, 핸드폰 인증도 간단합니다.
사이트 등록(제출)
+ 버튼을 눌러 사이트를 등록합니다.
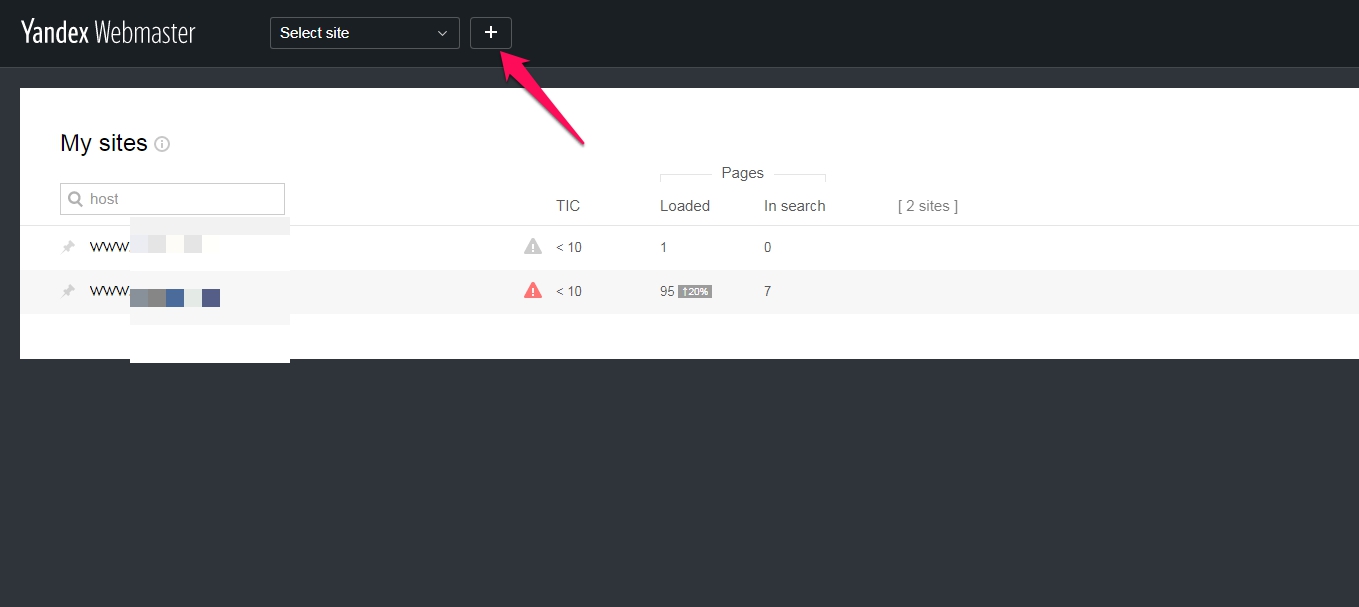
얀덱스는 소유권확인 수단으로 Meta tag, HTML file, DNS record를 사용하는데 저의 경우, 편리한 Meta tag 로 처리하였습니다. 각자 편리한 방법으로 소유권을 확인하세요.
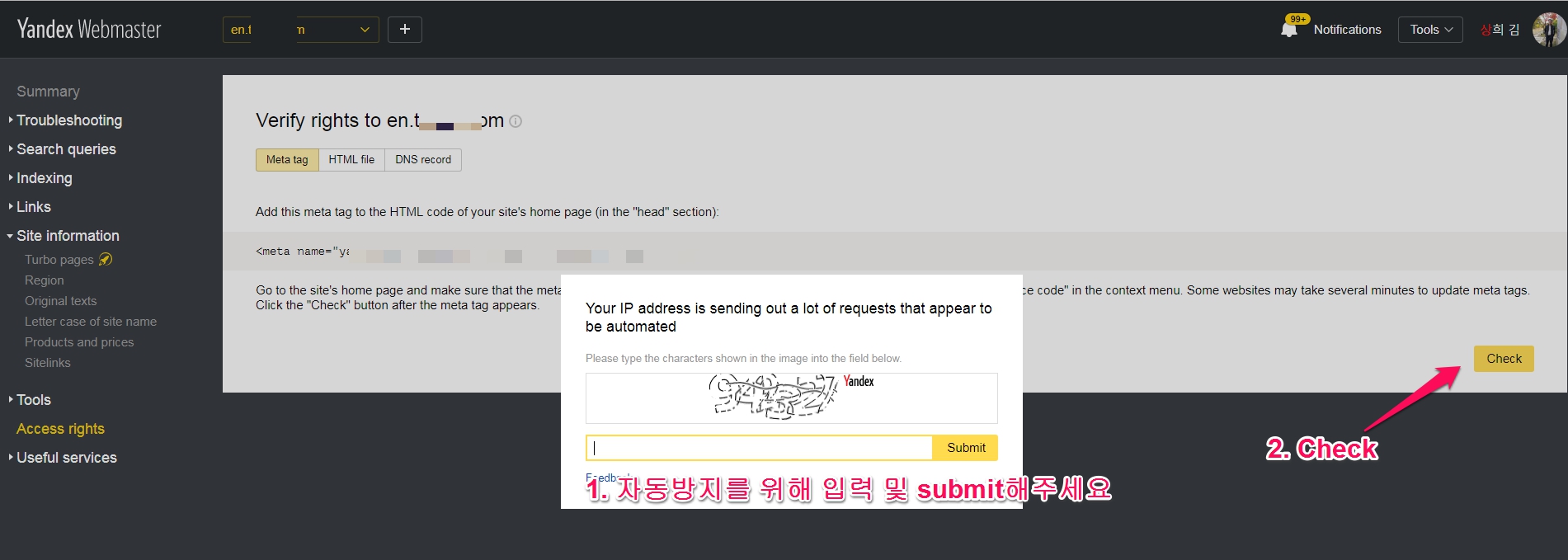
저의경우, SEO quake 라는 크롬 확장프로그램(SEO tool) 을 사용하는데 이것 때문에 자동입력방지를 위해 자꾸 숫자를 넣으라고 나오고 있습니다. 저처럼 SEO tool 을 사용하지 않는 분들은 바로 checking(소유권 확인) 하시면 소유권 확인을 완료하실 수 있을 것입니다.
참고로, 소유권 인증 여부와 어떻게 소유권을 인증했는지는 [Settings] ->[Access rights]에서 확인할 수 있습니다. 구글 서치콘솔처럼 다시 Meta tag을 살펴보고너 HTML file을 얻을 수는 없고 Confirmation code 정도를 얻을 수 있습니다. Meta tag나 HTML file을 다시 얻으려면 [Reset rights]를 하는 방법밖에 없습니다.
일정 기간이 지나면 아래와 같이 webmaster 가 그 결과들을 알려줍니다.
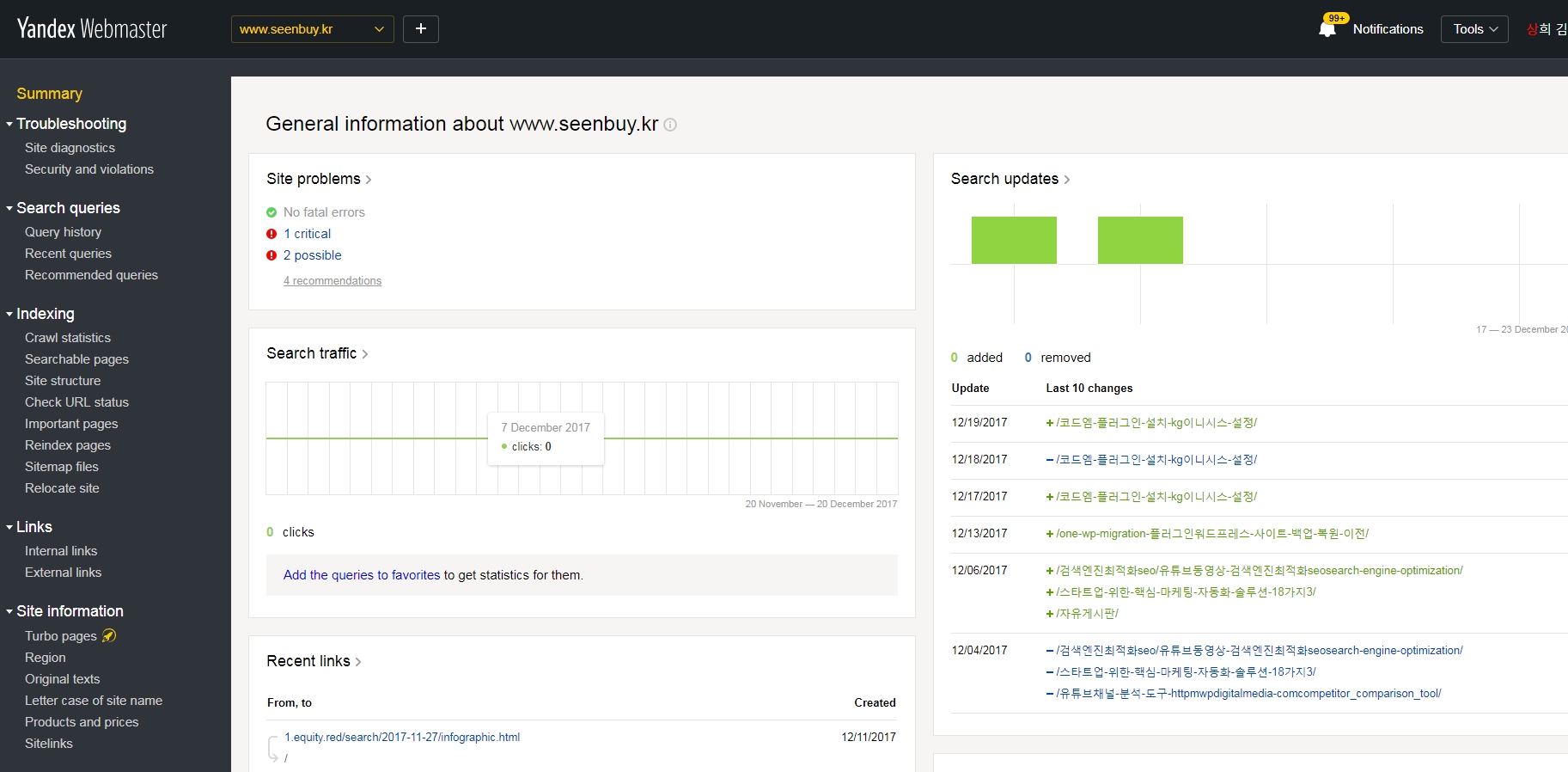
구성
웹마스터 도구는 아래와 같이 구성되어 있습니다. 구성요소별 설명은 차차하기로 하고 먼저 Indexing부분부터 정리하겠습니다.
- Summary
- Site quality
- Troubleshooting
- Search queries
- Indexing
- Links
- Site information
- Turbo pages
- Tools
- Settings
- Useful services
Summary
Site quality
Troubleshooting
Search queries
Indexing
Crawl statistics
Crawl statistics는 색인의 통계를 보여주고 Searchable pages는 검색결과페이지에 노출되고 있거나 노출될 페이지를 보여줍니다. 웹마스터도구에서 집중적으로 보아야할 중요부분입니다. Crawl statistics의 이미지를 보시면 색인된 페이지가 367 페이지입니다. [Searchable pages]->[Dictribution]에서 검색결과에 노출되거나 조만간 노출될 검색결과페이지를 살펴보니 20 페이지입니다.
색인된 페이지가 모두 검색결과페이지에 노출되는 것은 아닙니다.
색인(index)된 페이지의 통계를 볼 수 있습니다.
New and Chagned : [Recent changes]와 [All pages] 중 선택하여 볼 수 있습니다.
Crawl statics : [All pages]를 선택하시면 지금까지 색인된 전체 페이지를 확인할 수 있습니다.
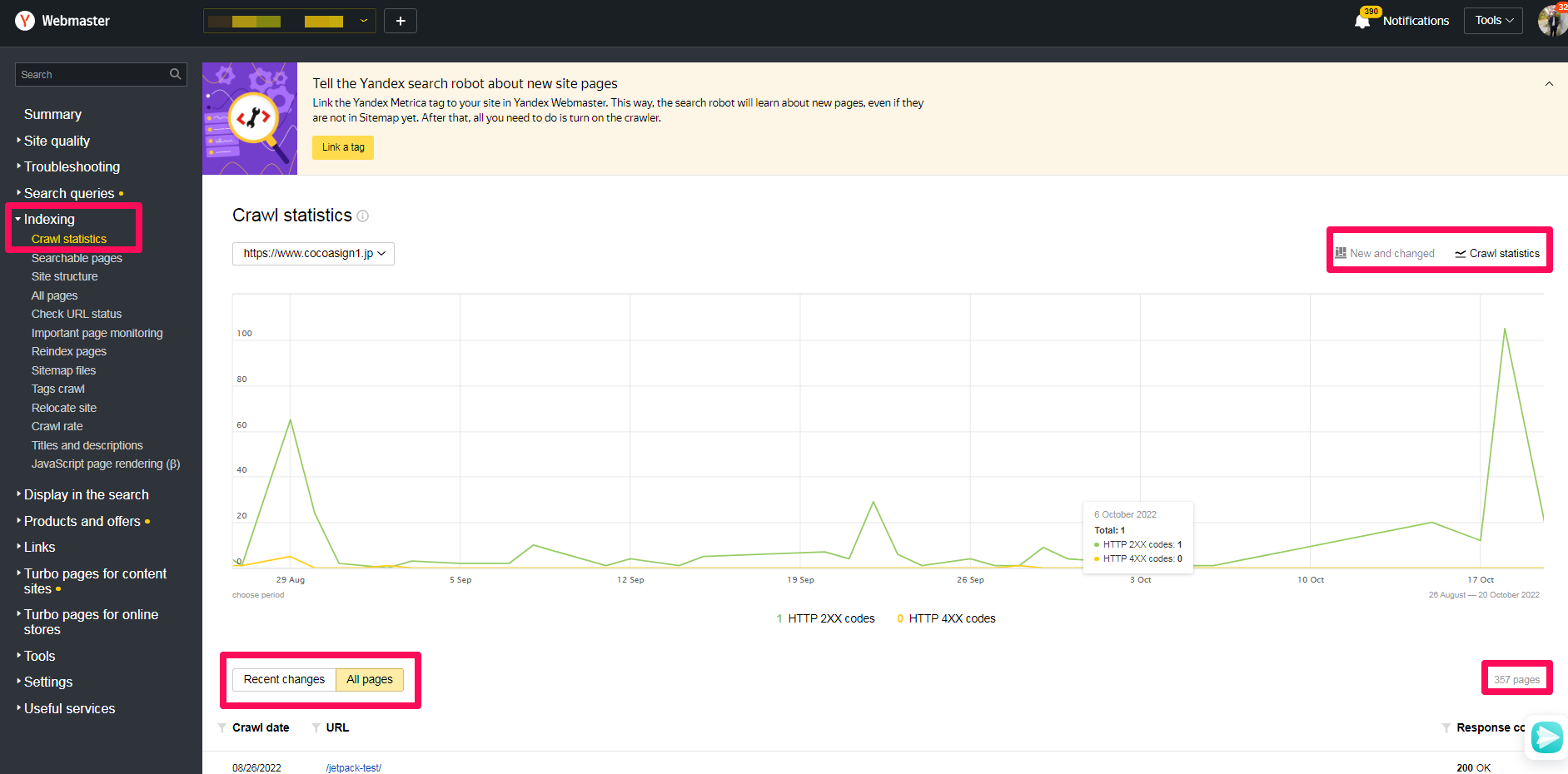
Searchable pages : 얀덱스는 색인은 비교적 잘 되고 적어도 수동색인이후에는 크롤링이 해당하므로 이 부분이 웹마스터도구의 핵심에 해당합니다.
얀덱스의 경우, 얀덱스의 조건을 만족하면 색인후 15일 정도 이후에 검색결과에 노출됨을 확인할 수 있었습니다.
검색결과에 표시되고 있거나 조만간 표시될 가능성이 있는 페이지들을 보여줍니다.
우측 상단 옵션은 의미는 아래와 같습니다. Dictribution는 현재 검색결과 페이지에 노출되고 있거나 조만건 노출될 페이지들이므로 이것을 살펴보시면 어떤 페이지가 얀덱스 검색결과페이지에 노출되고 있는지 또는 조만간 노출될 것인 정확히 확인할 수 있습니다. (참고로,. 검색쿼리로 site:www.abc.com을 사용하시면 현재 노출되고 있는 페이지만을 확인할 수 있습니다. )
- Added and removed —검색에 포함 및 제외된 페이지의 비율입니다.( The ratio of the pages included and excluded from the search.)
- Excluded — 검색에서 제외된 페이지의 역학입니다.(The dynamics of pages excluded from the search.)
- History — 검색에 포함된 페이지의 역학. 그래프의 각 세그먼트는 사이트 섹션에 해당합니다.(The dynamics of pages included in the search. Each segment of the graph corresponds to a site section.)
- Dictribution — 검색에 포함된 페이지 수입니다. 원형 차트의 각 세그먼트는 사이트 섹션에 해당합니다.
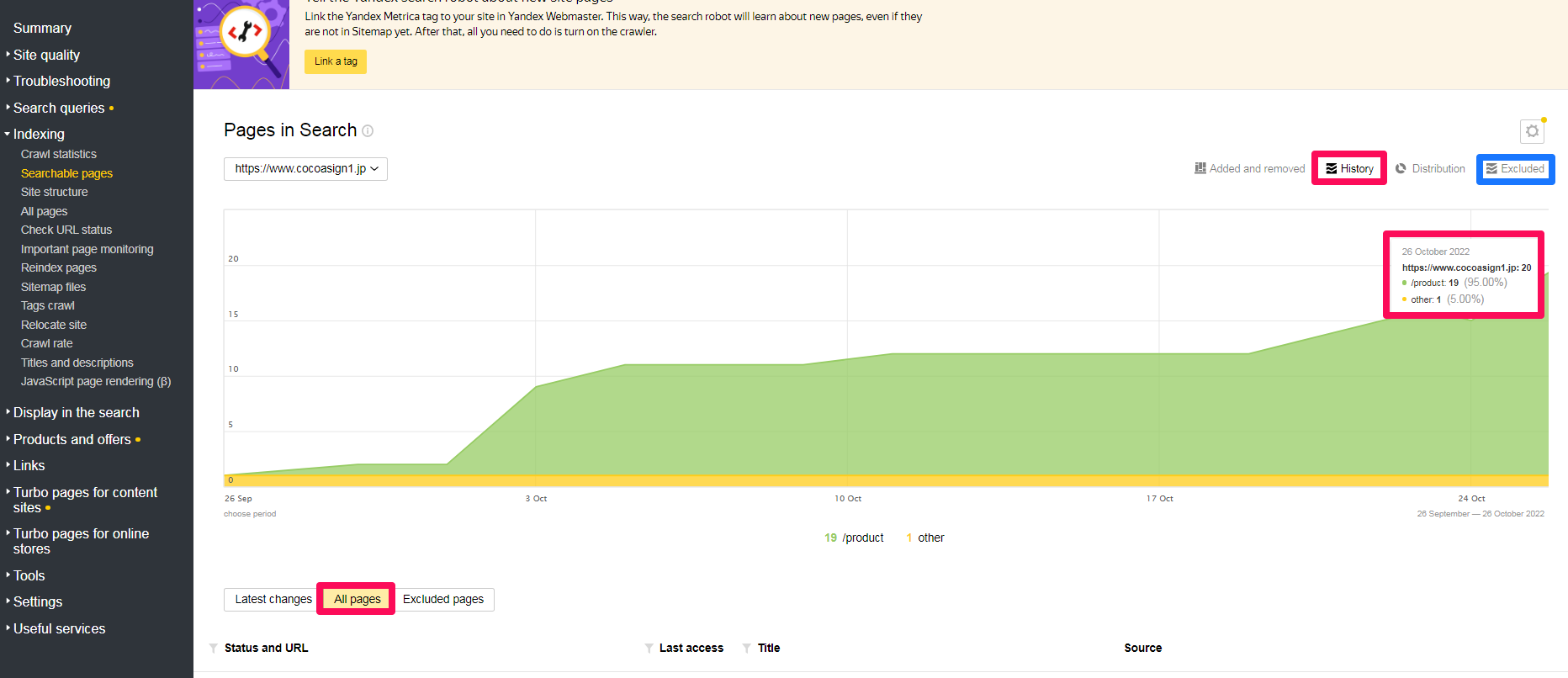
색인된 페이지가 모두 검색결과페이지에 노출되는 것은 아닙니다. 색인이 되었으나 노출(검색결과페이지에 표시)되지 않은 이유를 찾아야 합니다.
[Excluded]를 선택하시고 다시 [Excluded pages]를 선택하시면 검색결과페이지에 표시되지 않는 페이지들의 목록이 표시됩니다.
초록색의 Status를 보시면 검색결과페이지에 표시되지 않는 간단한 이유가 표시되며 끝에 … 를 클릭하시면 노랑색처럼 좀더 자세한 내용이 나오는데 ‘Read our recommendations‘는 관련성이 떨어지므로 pass해주세요.
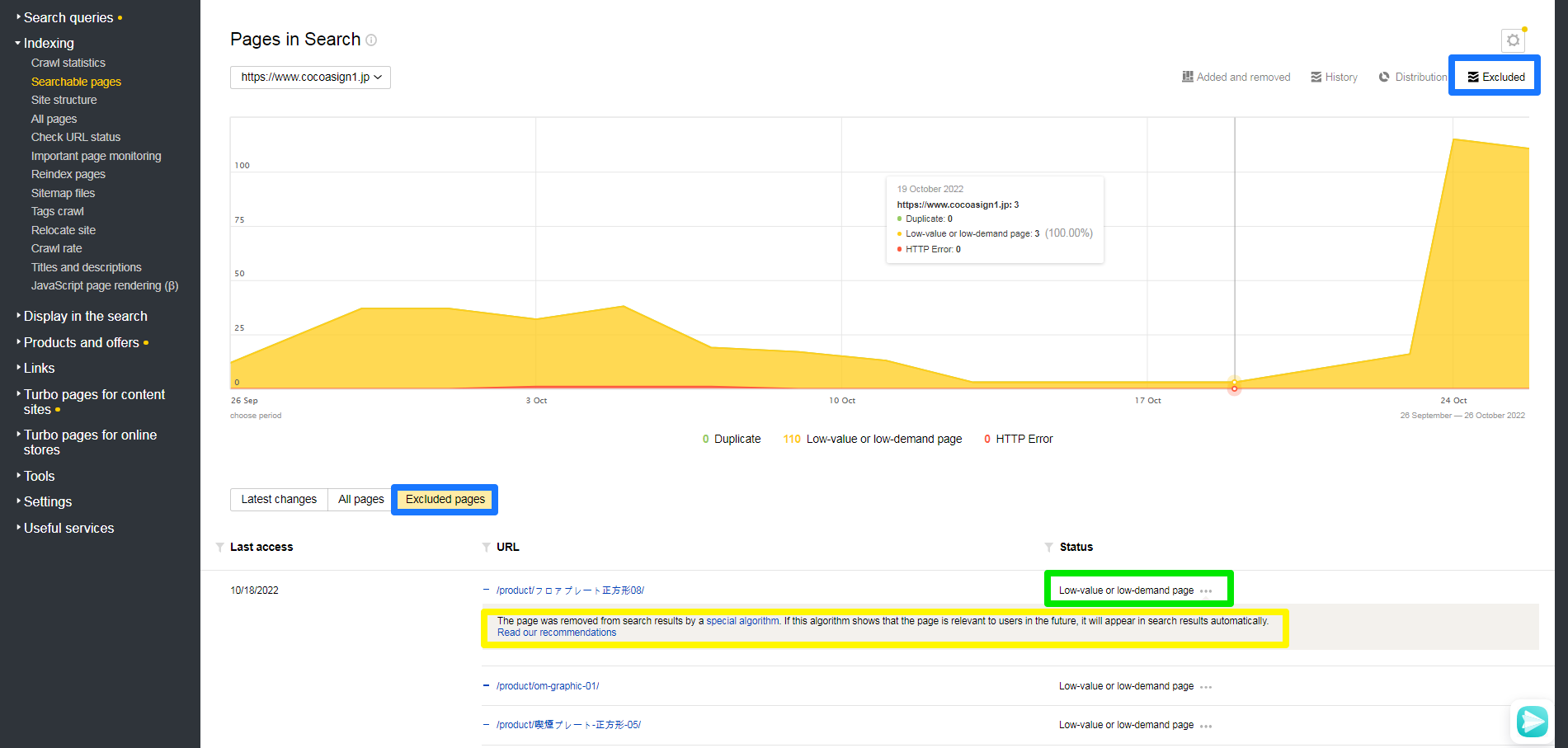
우측 맨아래 XLS, CVS로 다운로드하여 내용을 살펴보시면 처리 과정과 결과를 정리하는데 유용합니다.
(Status에 표시되는) 검색결과제외 페이지의 상태(Page statuses in the search)
이 테이블에서는 개요만 파악하고 해결책이 있는 아래의 ‘페이지 제외 이유와 해결책(Yandex Support의 Why are pages excluded from the search? )’를 살펴보고 해결책은 여기에 정리해 주세요.
| Page status in the web interface (웹 인터페이스의 페이지 상태) | Page status in the file (파일의 페이지 상태) | Description (설명) | Recommendations (권장 사항) |
|---|---|---|---|
| Low-value or low-demand page(가치가 낮거나 수요가 적은 페이지) | LOW_DEMAND | The algorithm decided not to include the page in search results because demand for the page is probably low. For example, this can happen if there’s no content on the page, if the page is a duplicate of pages already known to the robot, or if its content doesn’t completely suit user interests.The algorithm automatically checks the pages on a regular basis, so the decision may change later. To learn more, see Low-value or low-demand pages. (알고리즘은 페이지에 대한 수요가 낮기 때문에 검색 결과에 페이지를 포함하지 않기로 결정했습니다. 예를 들어, 페이지에 콘텐츠가 없거나, 페이지가 로봇에 이미 알려진 페이지와 중복되거나, 콘텐츠가 사용자의 관심사에 완전히 맞지 않는 경우에 발생할 수 있습니다.알고리즘은 정기적으로 페이지를 자동으로 확인하므로 나중에 결정이 변경될 수 있습니다. 자세한 내용은 가치가 낮거나 수요가 적은 페이지 를 참조하십시오 .) | To learn more, see Low-value or low-demand pages. (자세한 내용은 가치가 낮거나 수요가 적은 페이지 를 참조하십시오 .) |
| Excluded by Clean-param (Clean-param에서 제외) | CLEAN_PARAMS | The page was excluded from the search after the robot processed the Clean-param directive. (로봇이 Clean-param 지시문 을 처리한 후 페이지가 검색에서 제외되었습니다 .) | To get the page indexed, edit the robots.txt file. (페이지의 색인을 생성하려면 robots.txt 파일을 수정하세요.) |
| Duplicate (복제하다) | DUPLICATE | The page duplicates a site page that is already in the search. (페이지가 이미 검색에 있는 사이트 페이지를 복제합니다.) | Specify the preferred URL for the robot using a 301 redirect or the rel=”canonical” attribute.If the content of the pages differs, send them for reindexing to speed up the search database update. (301 리디렉션 또는 rel=”canonical” 속성 을 사용하여 로봇의 기본 URL을 지정 합니다.페이지의 내용이 다른 경우 색인을 다시 작성하도록 보내 검색 데이터베이스 업데이트 속도를 높입니다.) |
| Server connection error (서버 연결 오류) | HOST_ERROR | When trying to access the site, the robot could not connect to the server. (사이트에 액세스하려고 할 때 로봇이 서버에 연결할 수 없습니다.) | Check the server response, make sure that the Yandex robot isn’t blocked by the hosting provider.The site is indexed automatically when it becomes available for the robot. (서버 응답을 확인하고 Yandex 로봇 이 호스팅 제공업체에 의해 차단되지 않았는지 확인합니다.로봇이 사이트를 사용할 수 있게 되면 사이트가 자동으로 인덱싱됩니다.) |
| HTTP error(HTTP 오류) | HTTP_ERROR | An error occurred while accessing the page. (페이지에 액세스하는 동안 오류가 발생했습니다.) | Check the server response.If the problem persists, contact your site administrator or the server administrator. If the page is available at the moment, send it for reindexing. (서버 응답을 확인하십시오 .문제가 지속되면 사이트 관리자나 서버 관리자에게 문의하십시오. 현재 페이지를 사용할 수 있는 경우 색인을 다시 생성하도록 보내십시오 .) |
| Prohibited by the noindex element. (noindex 요소 에 의해 금지됩니다.) | META_NO_INDEX | The page was excluded from the search because it is prohibited from indexing (with the robots meta tag that contains the content=”noindex” or content=”none” directive). (페이지는 색인 생성이 금지되어 검색에서 제외되었습니다( content=”noindex” 또는 content=”none” 지시문 이 포함된 robots 메타 태그 사용).) | To get the page displayed in the search, remove the ban and send it for reindexing. (검색에 페이지를 표시하려면 차단을 제거하고 색인을 다시 생성하도록 보내십시오 .) |
| Non-canonical (비표준) | NOT_CANONICAL | The page is indexed by the canonical URL specified in the rel=”canonical” attribute in its source code. (페이지는 소스 코드 의 rel=”canonical” 속성에 지정된 표준 URL로 색인이 생성됩니다 .) | Correct or delete the rel=”canonical” attribute if it is specified incorrectly. The robot will track the changes automatically.To speed up the page information update, send the page for reindexing. (rel=”canonical” 속성이 잘못 지정된 경우 수정하거나 삭제합니다 . 로봇은 변경 사항을 자동으로 추적합니다.페이지 정보 업데이트 속도를 높이려면 색인 재지정을 위해 페이지를 보냅니다 .) |
| Secondary mirror (보조 미러) | NOT_MAIN_MIRROR | The page belongs to a secondary site mirror, so it was excluded from the search. (페이지는 보조 사이트 미러 에 속하므로 검색에서 제외되었습니다.) | |
| Unknown status (알 수 없는 상태) | OTHER | The robot has no up-to-date data on the page. (로봇은 페이지에 갱신된 데이터가 없습니다.) | Check the server response or prohibiting HTML elements.If the page can’t be accessed by the robot, contact the administrator of your site or server. If the page is available at the moment, send it for reindexing. (서버 응답을 확인 하거나 HTML 요소 를 금지 합니다 .로봇이 페이지에 액세스할 수 없는 경우 사이트 또는 서버 관리자에게 문의하세요. 현재 페이지를 사용할 수 있는 경우 색인을 다시 생성하도록 보내십시오 .) |
| Couldn’t download page (페이지를 다운로드할 수 없습니다) | PARSER_ERROR | When trying to access the page, the robot couldn’t get its content. (페이지에 액세스하려고 할 때 로봇이 콘텐츠를 가져올 수 없습니다.) | Check the server response or prohibiting HTML elements.If the problem persists, contact your site administrator or the server administrator. If the page is available at the moment, send it for reindexing. (서버 응답을 확인 하거나 HTML 요소 를 금지 합니다 .문제가 지속되면 사이트 관리자나 서버 관리자에게 문의하십시오. 현재 페이지를 사용할 수 있는 경우 색인을 다시 생성하도록 보내십시오 .) |
| In search (찾는 중) | REDIRECT_SEARCHABLE | The page redirects to another page but is included in the search. (페이지 가 다른 페이지로 리디렉션 되지만 검색에 포함됩니다.) | http에서 https에서 전환시 나올 수 있는 경우로 보입니다. |
| Redirect (리디렉션) | REDIRECT_NOTSEARCHABLE | The page redirects to another page. The target page is indexed. (페이지 가 다른 페이지로 리디렉션 됩니다. 대상 페이지가 인덱싱됩니다.) | Check the indexing of the target page. (대상 페이지의 인덱싱을 확인하십시오 .) |
| Disallowed in robots.txt (entire site) (robots.txt 에서 허용되지 않음 (전체 사이트)) | ROBOTS_HOST_ERROR | Site indexing is prohibited in the robots.txt file. The robot will automatically start crawling the page when the site becomes available for indexing. (robots.txt 파일 에서는 사이트 색인 생성이 금지되어 있습니다. 사이트가 색인을 생성할 수 있게 되면 로봇이 자동으로 페이지 크롤링을 시작합니다.) | If necessary, make changes to the robots.txt file. (필요한 경우 robots.txt 파일을 변경합니다.) |
| Disallowed robots.txt (page) (허용되지 않는 robots.txt (페이지)) | ROBOTS_TXT_ERROR | Site indexing is prohibited in the robots.txt file. The robot will automatically start crawling the page when the site becomes available for indexing. (robots.txt 파일 에서는 사이트 색인 생성이 금지되어 있습니다. 사이트가 색인을 생성할 수 있게 되면 로봇이 자동으로 페이지 크롤링을 시작합니다.) | If necessary, make changes to the robots.txt file. (필요한 경우 robots.txt 파일을 변경합니다.) |
| In search (찾는 중) | SEARCHABLE (검색 가능) | The page is included in search and can be displayed in search results for queries. (페이지는 검색에 포함되며 쿼리에 대한 검색 결과에 표시될 수 있습니다.) |
페이지 제외 이유와 해결책(Yandex Support의 Why are pages excluded from the search? )
아래와 같습니다.
| Reason for excluding a page (페이지 제외 이유) | Solution(해결책) |
|---|---|
| The page was considered low-value or in low-demand(페이지가 가치가 낮거나 수요가 낮은 것으로 간주됨) | The algorithm decided not to include the page in search results because demand for the page is probably low. For example, this can happen if there’s no content on the page, if the page is a duplicate of pages already known to the robot, or if its content doesn’t completely suit user interests.The algorithm automatically checks the pages on a regular basis, so the decision may change later. To learn more, see Low-value or low-demand pages. (알고리즘은 페이지에 대한 수요가 낮기 때문에 검색 결과에 페이지를 포함하지 않기로 결정했습니다. 예를 들어, 페이지에 콘텐츠가 없거나, 페이지가 로봇에 이미 알려진 페이지와 중복되거나, 콘텐츠가 사용자의 관심사에 완전히 맞지 않는 경우에 발생할 수 있습니다.알고리즘은 정기적으로 페이지를 자동으로 확인하므로 나중에 결정이 변경될 수 있습니다. 자세한 내용은 가치가 낮거나 수요가 적은 페이지 를 참조하십시오 .) : 저희의 경우, 일본 사이트를 만들면서 이 제외 사유를 접하게 되었는데, 이미 같은 이미지를 사용하고 내용이 거의 비슷한 다른 사이트가 있었는데, ‘ 페이지가 로봇에 이미 알려진 페이지와 중복되거나, ‘에 해당되어 제외된 것 같습니다. |
| An error occurred when the robot was loading or processing the page, and the server response contained HTTP status code 3XX, 4XX, or 5XX. (로봇이 페이지를 로드하거나 처리할 때 오류가 발생했으며 서버 응답에 HTTP 상태 코드 3XX, 4XX 또는 5XX가 포함되었습니다.) | To find the error, use the Server response check tool.If the page is accessible to the robot, make sure that:The information about pages is present in the Sitemap file.The Disallow and noindex prohibiting directives and the noindex HTML element in the robots.txt file prevent only technical and duplicate pages from indexing. (오류를 찾으려면 서버 응답 확인 도구를 사용하십시오.로봇이 페이지에 액세스할 수 있는 경우 다음을 확인하십시오.페이지에 대한 정보는 Sitemap 파일에 있습니다.robots.txt 파일 의 Disallow 및 noindex 금지 지시문과 noindex HTML 요소는 기술 페이지와 중복 페이지만 색인을 생성하는 것을 방지합니다.) |
| Page indexing is prohibited in the robots.txt file or using a meta tag with the noindex directive. (robots.txt 파일에서 또는 noindex 지시문 과 함께 메타 태그를 사용하는 페이지 인덱싱은 금지되어 있습니다.) | Remove the prohibiting directives. If you didn’t place the ban in robots.txt yourself, contact your hosting provider or domain name registrar for details.Also make sure that the domain name isn’t blocked due to the registration period expiry. (금지 지시문을 제거하십시오. robots.txt 에 직접 금지 조치를 취하지 않았다면 호스팅 제공업체나 도메인 이름 등록 기관에 자세한 내용을 문의하세요.또한 등록 기간 만료로 인해 도메인 이름이 차단되지 않았는지 확인하십시오.) |
| The page redirects the robot to other pages (페이지는 로봇을 다른 페이지로 리디렉션합니다.) | Make sure that the excluded page should actually redirect users. To do this, use the Server response check tool. (제외된 페이지가 실제로 사용자를 리디렉션해야 하는지 확인하십시오. 이렇게 하려면 서버 응답 확인 도구를 사용하십시오.) |
| The page duplicates the content of another page (페이지가 다른 페이지의 콘텐츠를 복제합니다.) | If the page is identified as duplicate by mistake, follow the instructions in the Duplicate pages section. (페이지가 실수로 중복으로 식별된 경우 중복 페이지 섹션의 지침을 따르십시오.) : 이것은 같은 사이트내에서 중복 페이지가 있는 경우를 말하는 것으로 보이고 외부 사이트와 비교는 아닌 것 같습니다. 외부 사이트와의 중복은 ‘The page was considered low-value or in low-demand(페이지가 가치가 낮거나 수요가 낮은 것으로 간주됨)’으로 표시되는 것 같습니다. |
| The page is not canonical (페이지가 표준 이 아닙니다.) | Make sure that the pages should actually redirect the robot to the URL specified in the rel=”canonical” attribute. (페이지가 실제로 로봇을 rel=”canonical” 속성 에 지정된 URL로 리디렉션해야 하는지 확인합니다 .) |
| The site is recognized as a secondary mirror (사이트가 2차 미러 로 인식됨) | If the sites are grouped by mistake, follow the recommendations in the Separating site mirrors section. (사이트가 실수로 그룹화된 경우 사이트 미러 분리 섹션의 권장 사항을 따르십시오.) |
| Violations are found on the site (사이트에서 위반 사항이 발견되었습니다.) | You can check this by going to the Troubleshooting → Security and violations page in Yandex.Webmaster. (Yandex.Webmaster 의 문제 해결 → 보안 및 위반 페이지 로 이동하여 이를 확인할 수 있습니다 .) |
Site structure
Check URL status
Check URL status 와 Reindex pages에서 서비스하는 내용은 “색인 생성을 추적하고 검색 상태 변경에 대한 알림을 받으려면 중요 페이지 목록에 URL을 추가하십시오.(Add URL to your list of important pages in order to track its indexing and get notified about changes to its status in Search.)”으로 같습니다.
차이는 Check URL status 는 상태를 확인하고 크롤링을 요청하는 것이고 Reindex pages는 크롤링 상태를 확인하지 않고 바로 크롤링을 요청한다는 점입니다. 또한 Check URL status는 확인하고자하는 URL 의 상태를 확인하고 주요한 페이지로 등록시켜 [Important page monitoring]에서 모니터링할 수 있습니다.
- 사이트에 대한 권한을 확인한 경우 로봇이 사이트 페이지에 대해 알고 있는지 확인할 수 있습니다.
- URL 필드에 전체 페이지 URL 또는 “/”로 시작하는 사이트 루트의 상대 경로 만 입력하십시오.
- 정보 수집 및 처리에는 일반적으로 최대 2 분이 걸립니다. 때로는 몇 시간이 걸릴 수 있습니다. 시스템이 데이터 처리를 완료하자마자 보고서 상태가 “준비(Ready)”로 전환됩니다.
- HTTP 상태가 무엇인지 보여줍니다. 예를들면, 200이면 OK(정상), 500이면 Internal Server Error이라는 의미입니다. 이것은 [Indexing] > [Crawl statistics]에 집계되어 표시됩니다.
Important page monitoring
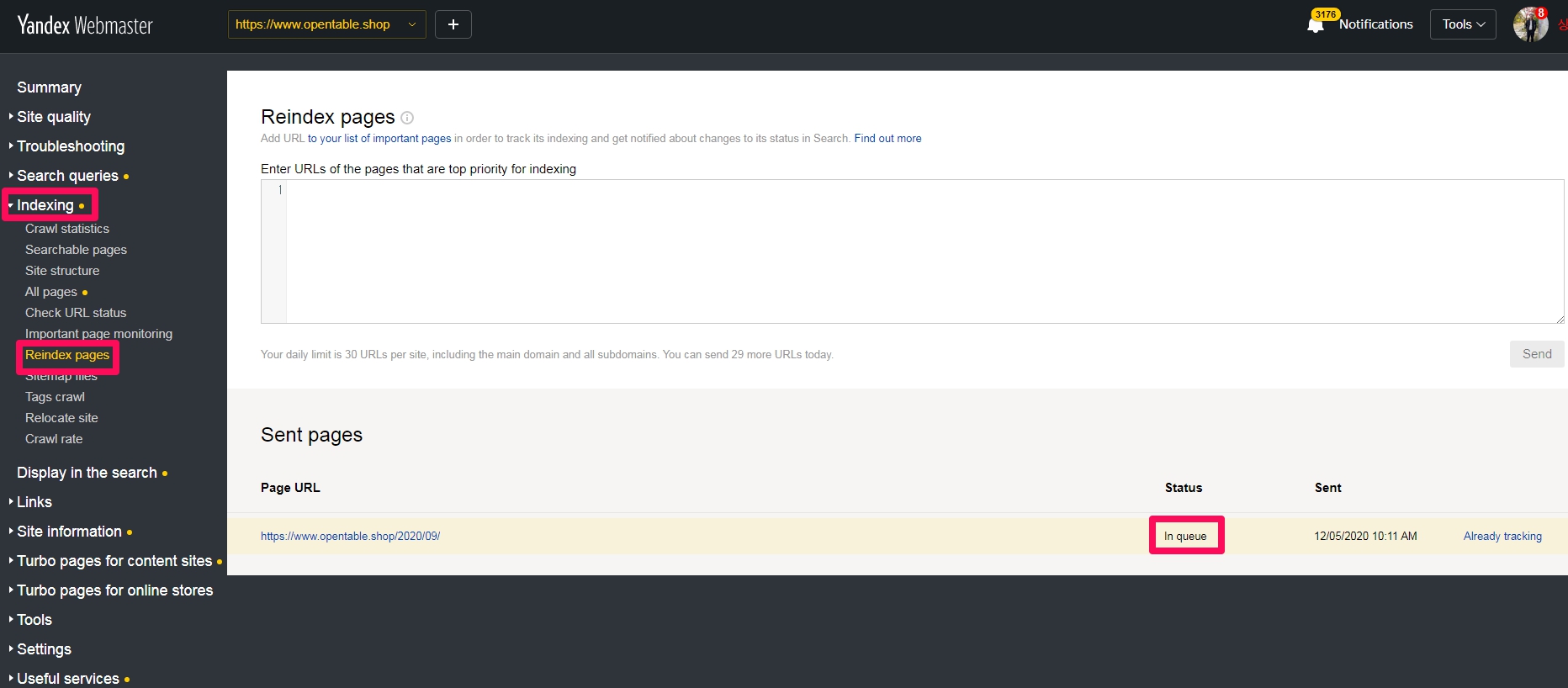
Reindex pages
구글서치콘솔의 [Fetch as google], 네이버 웹마스터 도구의 [웹페이지 수집]에 해당하는 것입니다. Reindex pages는 하루에 20개까지 인덱스 요청을 할 수 있습니다.
이 섹션은 Yandex에 새로운 페이지 및 업데이트된 페이지를 알리는 데 도움이 됩니다. 또한 자연적으로 얀덱스 검색 로봇이 크롤링하기를 기다리기 이전에 빨리 크롤링 되기를 원하시는 페이지를 수집 요청하는데 이용할 수 있습니다. 그러나 색인이 되지 않은 페이지를 강제로 색인 요청하는데 더 많이 사용됩니다. 페이지 주소를 보내면 해당 상태를 볼 수 있습니다.
- “In queue” — 크롤링을 위해 페이지는 얀덱스 검색 로봇에게 전송됩니다. 요청은 3 일 이내에 처리됩니다.
- “Crawled” — 로봇이 페이지를 크롤링했습니다. 페이지 정보는 2 주 내에 검색에서 업데이트됩니다.
- “Error” — 로봇이 페이지에 접근할 수 없습니다.
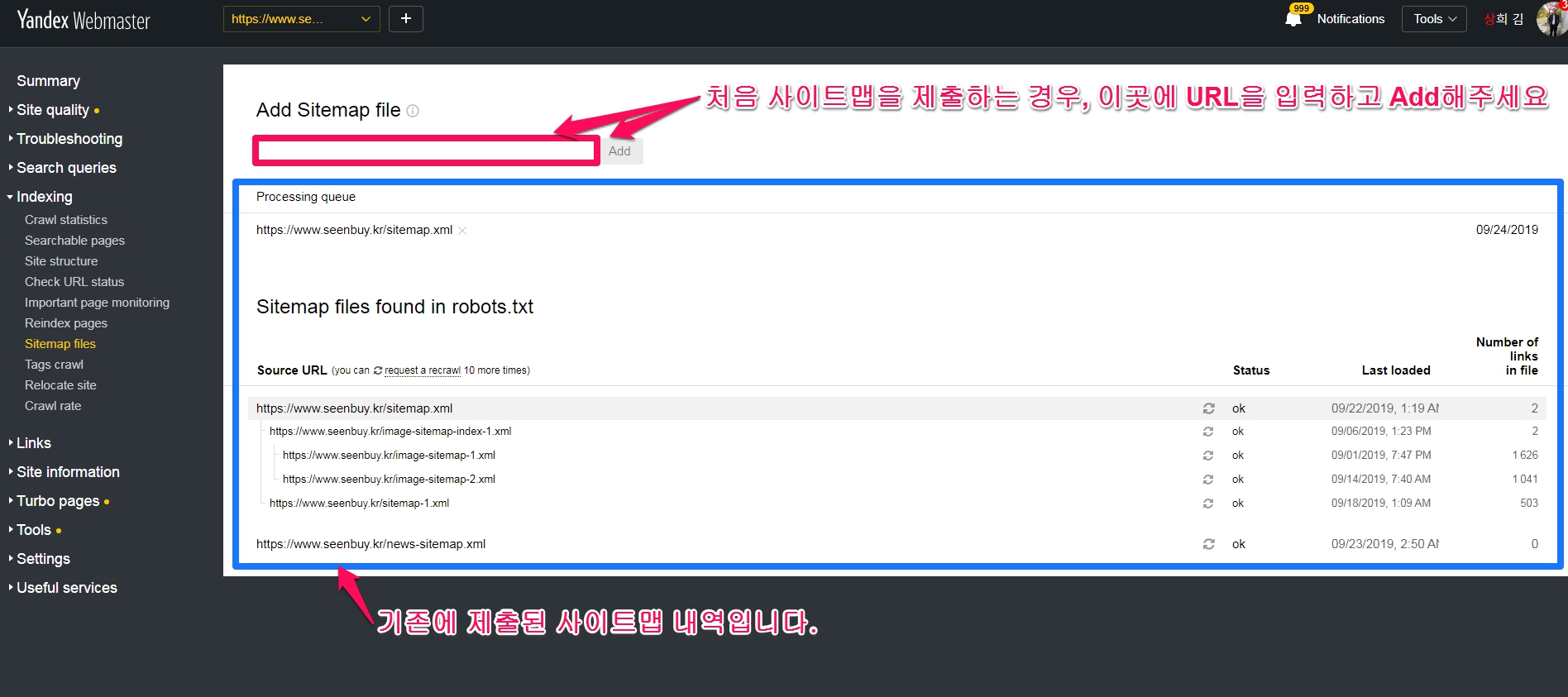
Sitemap files
사이트맵(sitemap.xml)을 신규로 제출하거나 이미 제출했던 내역을 확인할 수 있습니다.
robots.txt 에서 사이트맵 경로를 알려주면 “Sitemap files found in robots.txt”와 같이 나오면서 사이트맵의 계층구조와 상태 그리고 링크된 파일의 숫자까지 상세히 보여줍니다.
Tags crawl
Tags crawl 의 중요성
검색엔진들은 크롤링 -> 데이터 베이스에 저장 -> 정리(색인)의 과정을 거쳐 검색자에게 검색결과를 보여줍니다. 얀덱스도 또한 같습니다.
Yandex 로봇이 정기적으로 사이트 페이지를 크롤링하는 경로는
- 내부 및 외부 링크.
- 사이트 맵 파일 에 지정된 링크
- Yandex.Metrica 데이터
입니다.
얀덱스에서 색인후 노출이 잘 되기를 원하신다면 자사/자신의 웹페이지는 내부 링크들로 잘 연결되어 있는지, 외부에 내부로 백링크를 많이 걸어주었는지, 사이트맵 파일은 잘 만들어젔고 검색 로봇이 잘 가지고 갈수 있도록 구성했는지(혹시 robots.txt 에서 검색엔진의 접근을 막지 않았는지) 그리고 Yandex_Metrica 의 사이트 추적 태그를 설치했는지 확인하는 것이 핵심입니다.
Yandex 로봇은 다양한 소스( 내부 및 외부 링크. 사이트 맵 파일 에 지정된 링크, Yandex.Metrica 데이터 ) 에서 사이트의 페이지에 대해 크롤링합니다. 그중 하나가 Yandex.Metrica 추적 태그입니다.
[Tags crawl] 는 Yandex.Metrica 태그가 있는 페이지에서 크롤링을 금지하거나 허용할 수 있습니다. 허용하시게 되면 크롤링 속도를 높힐 수 있고 색인 및 검색노출 시간도 앞당기실 수 있습니다. 이런 이유로 [tags crawl]를 통해 크롤링을 허용하는 것은 중요한 작업입니다.
얀덱스와 얀덱스.메트리카의 연동( Tag ID 연결하기 )
처음 접속하시면 Tag ID 가 안 보이실 것입니다. 이 기능을 사용하시려면 먼저, 아래의 [Settings] -> [Yandex.Metrica tags]에서 tad id 를 등록(얀덱스와 얀덱스.메트리카를 연동)해주셔야 합니다.( Yandex.Metrica tag 설정하기로 이동 )
그런 다음 Yandex.Webmaster에서 크롤링 허용 옵션을 허용으로 선택합니다.
크롤링 허용방법
[색인 생성(Indexing)] → [태그 크롤링(Tags crawl)] 페이지에서 크롤링 허용 옵션을 클릭하시어 활성화하십시오 .
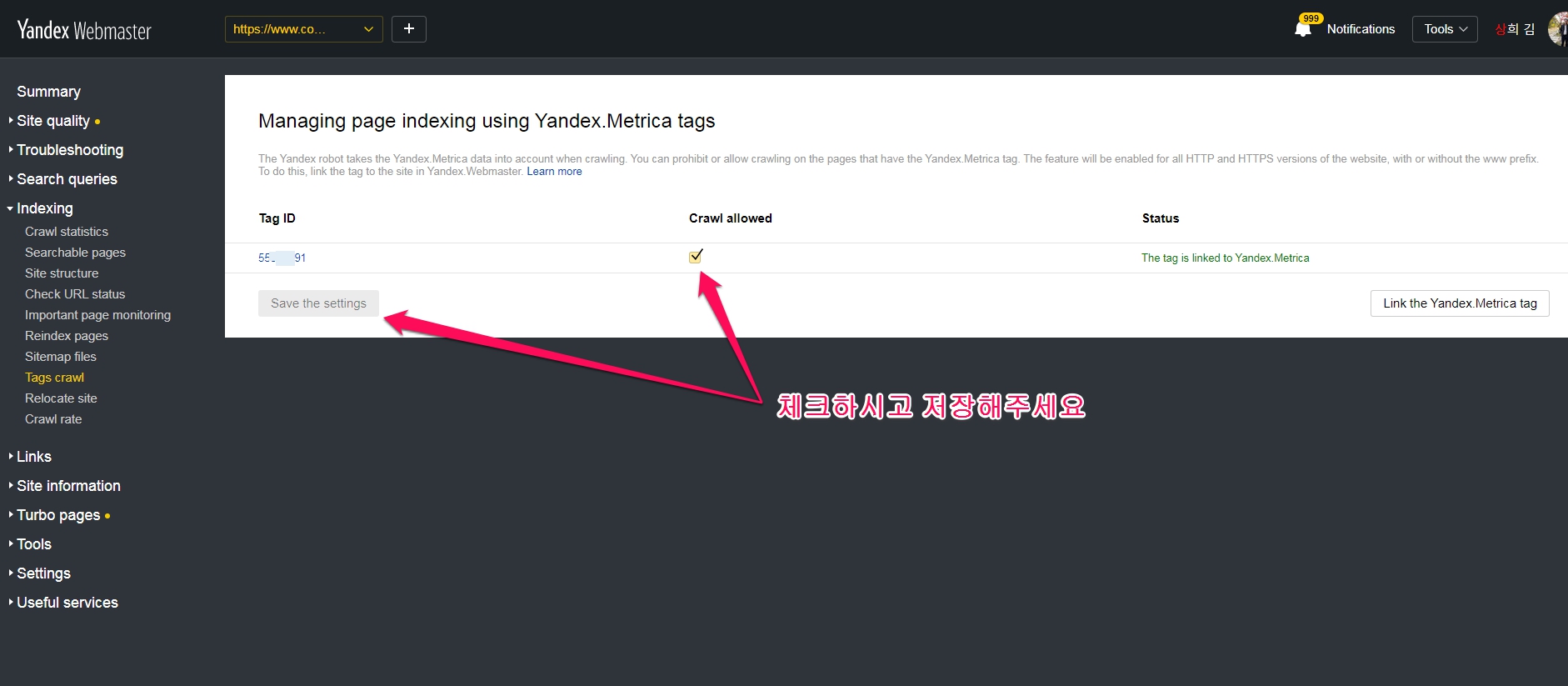
이 옵션은 HTTP 또는 HTTPS 프로토콜을 통해 “www”접두사를 사용하거나 사용하지 않고 모든 버전의 사이트에서 사용할 수 있습니다.
로봇이 Yandex.Metrica 데이터를 사용하여 사이트를 크롤링하지 못하게하려면 태그 옆에있는 크롤링 허용 옵션을 끄고 설정을 저장하십시오. 그 후 로봇은 태그가 포함 된 새 사이트 페이지를 크롤링하지 않지만 다른 소스 에서 해당 페이지를 찾을 수 있습니다 .
참고로, 로봇이 페이지 색인을 생성하지 못하도록하려면 robots.txt 파일 인 “robots”메타 태그를 사용하십시오 . 또는 사이트 삭제 를 하는 방법이 있습니다.
Relocate site
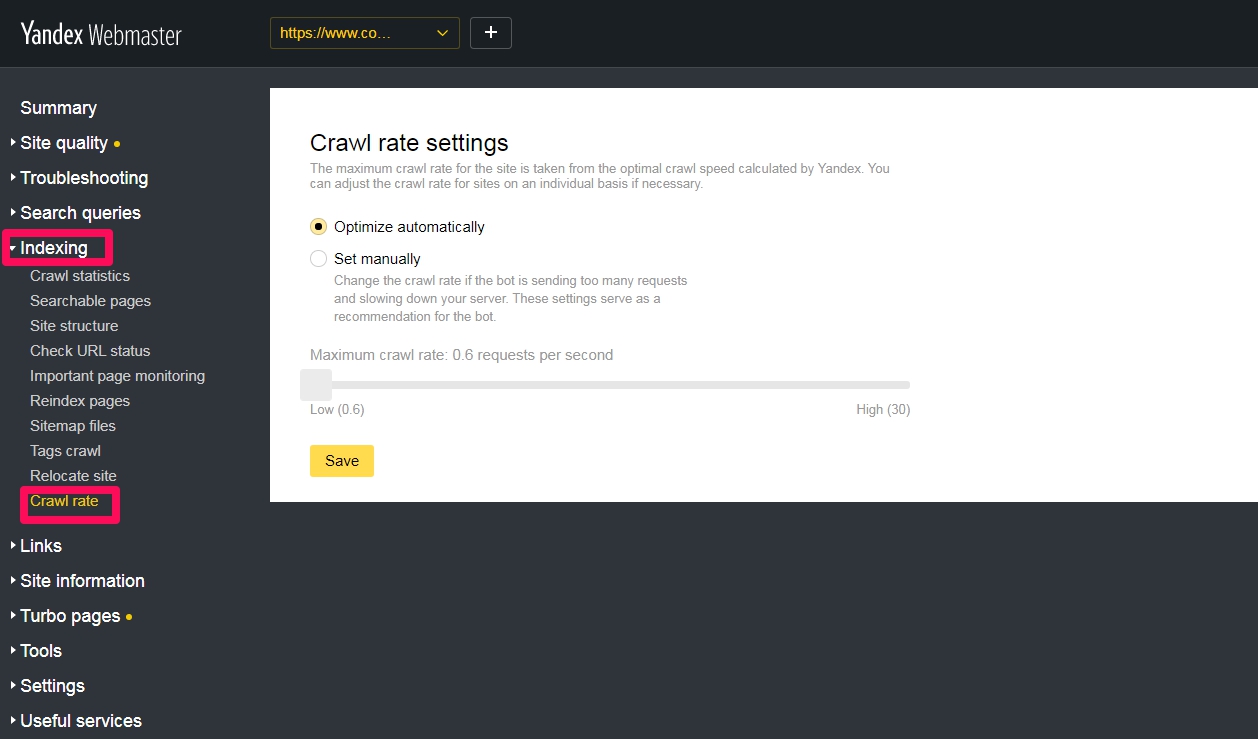
Crawl rate ( 크롤링 속도 설정 )
사이트의 최대 크롤링 속도는 Yandex에서 계산 한 최적의 크롤링 속도에서 가져옵니다. 필요한 경우 사이트의 크롤링 속도를 개별적으로 조정할 수 있습니다.
얀덱스 검색 로봇이 너무 많은 요청을 보내어 서버 속도를 저하시키는 경우, 클롤링 속도를 수동 설정(Set Manually)에서 변경할 수 있습니다. Low으로 갈 수록 드물게 크롤링하게 되고 최소값은 초당 0.6회이며 High로 갈수록 자주 크롤링하게 되는 데 최대값은 초당 30회입니다.
서버 속도를 저하하는 경우가 아니라면 Optimize automatically(자동 최적화)로 나두는 것이 좋겠습니다.
Links
Site information
Turbo pages
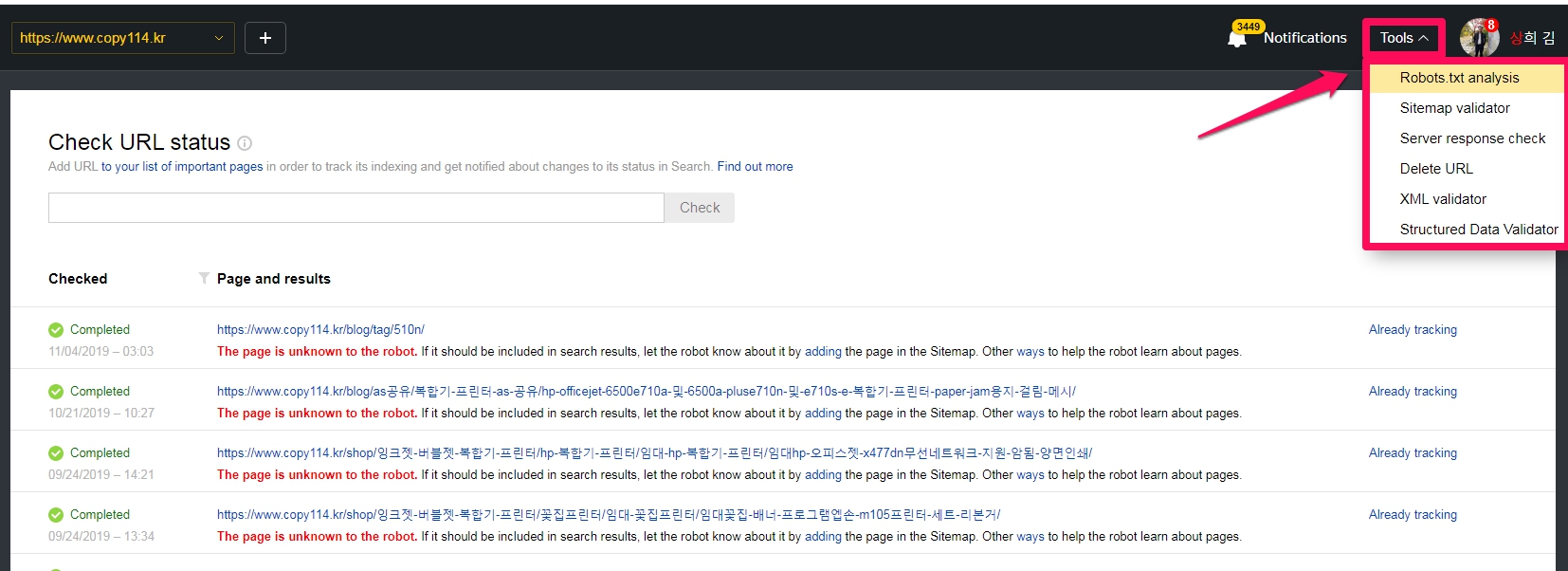
Tools
- Robots.txt 분석(Robots.txt analysis) : 사이트 의 robots.txt 파일이 올바르게 구성되었는지 확인하고 특정 URL의 색인 생성이 허용되는지 확인하고 파일 변경 내역을 볼 수 있습니다. 더 알아보기
- 사이트맵 검사기(Sitemap validator) : 사이트 의 Sitemap 파일이 올바르게 구성되었는지 확인하는 데 도움이 됩니다. 확인 후 파일을 Yandex.Webmaster에 업로드 할 수 있으므로 로봇이 해당 콘텐츠를 빠르게 크롤링했습니다. 더 알아보기
- 서버의 응답 확인(Checking the server’s response) : 주요 Yandex 로봇에 대해 사이트 페이지를 사용할 수 있는지 확인하는 데 도움이됩니다. 더 알아보기
- 검색 결과에서 페이지 제거(Removing pages from search results) : 검색 결과에서 특정 사이트 페이지, 디렉토리 또는 전체 사이트를 제거하는 속도를 높일 수 있습니다. 삭제하고자하는 페이지를 빠르게 삭제할 수 있어 훌륭한 기능인데… 얀덱스에서 색인에만 적용할 수 있고 다른 검색엔진에는 적용할 수 없는 점이 아쉽습니다. 더 알아보기
- 모바일 호환성을위한 감사 페이지(Audit pages for mobile compatibility) : 사이트 페이지가 모바일 장치에 최적화되어 있는지 확인하는 데 도움이됩니다. 더 알아보기
- XML 유효성 검사기(XML validator) : Yandex Affiliate 프로그램 에 참여하기 위해 생성 된 사이트 문서 (구문, 구조, 콘텐츠 모델 및 데이터 유형)의 XSD 스키마를 확인하는 데 도움이 됩니다 . 더 알아보기
- 구조화된 데이터 검사기(Structured data validator) : 사이트에서 microformats , Schema.org , Open Graph , microdata HTML 및 RDFa 의 마이크로 마크 업을 확인하는 데 도움이 됩니다. 구글서치콘솔이전의 버전인 구글 웹마스터도구에서 제공하던 구조화 데이터가 떠오릅니다. 훌륭한 기능힙니다. 현재는 Google 구조화된 데이터 테스팅 도구( ( https://search.google.com/structured-data/testing-tool ) 를 통해 서비스하는데, 코드스니펫을 완벽하게 분석해주어 검색엔진최적화 중 스니펫 부분을 완벽하게 진단해주므로 꼭 참조하세요. 더 알아보기
[참고]Tools은 우측 상단의 Tool 바로가기버튼을 이용하여 보다 쉽게 이용할 수 있습니다.
Robots.txt 분석(Robots.txt analysis)
사용법
- 검사할 필드에 robots.txt 의 웹 사이트의 주소를 입력합니다. 예 : https://example.com/robots.txt. 소유권을 주장하지 않은 모든 웹사이트의 robots.txt를 검증할 수 있으므로 꼭 활용하세요.
 아이콘을 클릭하십시오 .
아이콘을 클릭하십시오 . - robots.txt 의 내용과 분석 결과는 아래와 보여집니다.
아래의 이미지에는 에러의 내용으로 ‘Unknown directive found(알 수없는 지시문이 발견되었습니다)’ 이 보입니다.
Sitemap: https://www.copy114.kr/sitemap.xml
와 같이 지시문을 작성해 주어야 하는데 아래와 같이 “Sitemap : “을 빼먹은 경우입니다.
https://www.copy114.kr/sitemap.xml
오류(Errors)
사이트맵 검사기(Sitemap validator)
사용법
파일 내용을 확인하려면 사이트 맵 검사기 페이지를 열고 다음 단계를 따르십시오.
- 다음 방법 중 하나를 사용하여 파일을 추가합니다.
- 파일 내용 ( text (텍스트) 옵션) : 파일 내용을 필드에 복사합니다. 유효성 검사 오류가있는 경우 파일을 편집하고 다시 확인할 수 있어 편리합니다.
- 파일 자체 ( file (파일) 옵션) : 사이트 디렉토리에서 파일을 업로드하거나 필드로 드래그하십시오.
- 파일 링크 ( URL 옵션) : 필드에 파일 링크를 입력하십시오 (예 : https://example.com/sitemap.xml). 이 옵션을 이용하면 타사 사이트의 사이트맵도 유효성을 검증할 수 있습니다.
- 확인을 클릭 합니다.
유효성 검사 오류가 발견되면 Sitemap 오류 참조 섹션을 참조 하세요 .
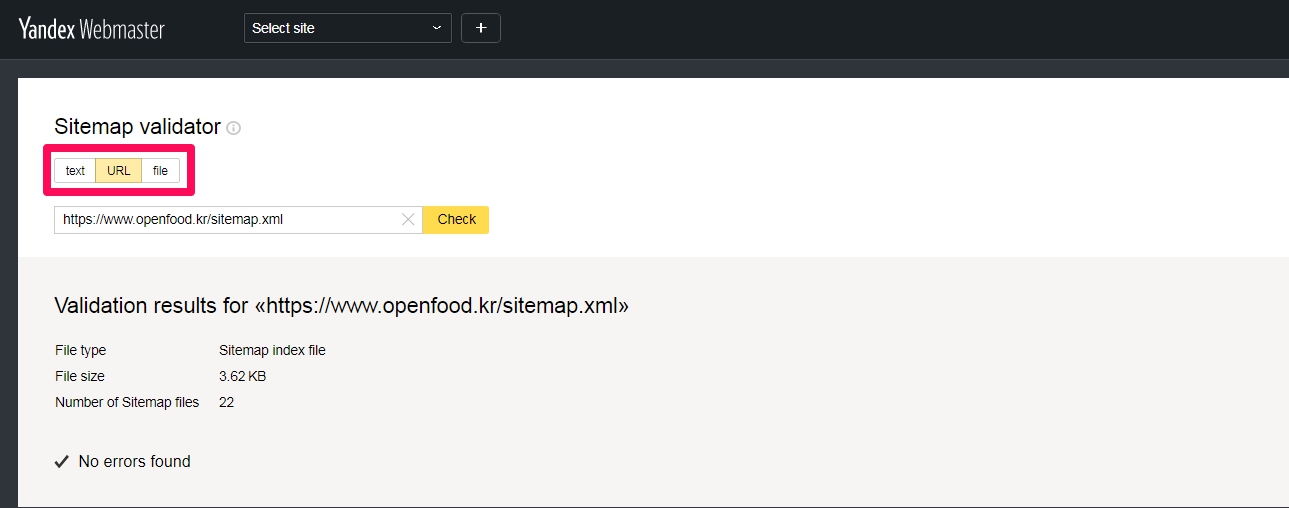
유효성 검사 및 정정후 다음 조치
Yandex.Webmaster ( Indexing → Sitemap files ) 에 Sitemap 파일을 업로드하면 로봇이 정기적으로 사이트를 처리하고 사이트 업데이트에 대해 알 수 있습니다.
Yandex.Webmaster에서 로봇이 파일을 인덱싱하는시기를 확인하고 업데이트에 대해 알릴 수 있습니다. Sitemap 파일 섹션 에서 자세히 알아보십시오 .
유효성 검사에 표시되는 오류(Errors)와 경고들( Sitemap errors reference )
오류(Errors)
사이트 맵 파일을 처리 할 때 발생하는 error(오류) 목록입니다.
| Error(오류) | 상세 설명(Description) |
|---|---|
| Not indexed.(색인이 생성되지 않았습니다.) | 사이트 맵 파일 을 다운로드하지 못했습니다 . 파일 URL이 올바르지 않을 수 있습니다.(Failed to download sitemap file. File URL might be incorrect.) |
| Maximum file size exceeded(최대 파일 크기를 초과했습니다.) | Sitemap 파일 크기가 50MB를 초과합니다.(Sitemap file size exceeds 50 MB.) |
| HTTP error(HTTP 오류) | 사이트 맵 파일 을 다운로드하려고 할 때 200이 아닌 HTTP 상태가 수신되었습니다.(When trying to download the sitemap file, HTTP status other than 200 was received.) |
| Invalid URL(잘못된 URL) | 사이트 맵 파일 의 잘못된 URL 이 지정되었습니다.(Invalid URL of the sitemap file is specified.) |
| Connection lost(연결이 끊어졌습니다.) | 사이트 맵 파일을 로드 할 때 서버 연결이 종료되었습니다 .(Server terminated connection when loading the sitemap file.) |
| DNS error(DNS 오류) | DNS 오류로 인해 파일을 다운로드하지 못했습니다. 파일 URL이 올바르지 않을 수 있습니다.(Failed to download the file because of DNS error. File URL might be incorrect.) |
| Connection failed(연결에 실패) | 사이트 맵 서버 연결에 실패 파일 다운로드에 실패했습니다.(The Sitemap file failed to download, because the server connection failed.) |
| The URL is forbidden in robots.txt(URL은 robots.txt 에서 금지되어 있습니다.) | robots.txt 파일 에서 사이트 맵 파일 의 URL 이 금지되어 있으므로 다운로드 할 수 없습니다. robots.txt 파일 및 사이트 맵 파일 주소 의 정확성을 확인하세요 .(The URL of the sitemap file is prohibited in the robots.txt file and therefore it could not be downloaded. Check the correctness of the robots.txt file and thesitemap file address.) |
| Incorrect HTTP response(잘못된 HTTP 응답) | 웹 서버 응답이 HTTP 프로토콜과 일치하지 않아 Sitemap 파일을로드하지 못했습니다.(Sitemap file failed to load because the web server response doesn’t match HTTP protocol.) |
| Response contains no data(응답에 데이터가 없습니다.) | 사이트 맵 파일을 다운로드 할 때 서버에서 빈 문서를 반환했습니다.(When downloading the sitemap file, the server returned an empty document.) |
| Extraction error(추출 오류) | gzip으로 압축 된 Sitemap 파일의 압축 을 푸는 중에 오류가 발생했습니다.(An error occurred while unpacking the Sitemap file compressed with gzip.) |
| Tag found more than once(두 번 이상 발견 된 태그) | 지정된 태그는 주어진 컨텍스트에서 한 번만 발생해야합니다.(The specified tag should occur in the given context only once.) |
| Unknown tag(알 수없는 태그) | 지정된 태그는 주어진 컨텍스트에서 발생하지 않아야합니다.(The specified tag should not occur in the given context.) |
| Tag not found(태그를 찾을 수 없습니다.) | 필수 태그가 없습니다.(Required tag is missing.) |
| Incorrect page address(잘못된 페이지 주소) | URL이 표준과 일치하지 않습니다.(The URL does not match to the standard.) |
| Incorrect URL (does not correspond to Sitemap index file location).(잘못된 URL ( Sitemap 색인 파일 위치와 일치하지 않음 )) | Sitemap 파일 위치는이 파일에 포함 할 수있는 URL 집합을 결정합니다. 디렉토리에있는 파일은 동일한 디렉토리 또는 하위 디렉토리의 URL을 포함해야합니다. 자세한 내용은 Sitemap 파일 위치를 참조하십시오.(Sitemap file location determines the set of URLs that you can include in this file. A file located in a directory must contain a URL from the same directory or its subdirectories. For details, see Sitemap file location.) |
| URL too long(URL이 너무 깁니다.) | URL 길이가 제한 (1024 자)을 초과합니다.(URL length exceeds the limit (1024 characters).) |
| Tag cannot be empty(태그는 비워 둘 수 없습니다.) | 지정된 태그는 비워 둘 수 없습니다.(The specified tag must not be empty.) |
| Tag cannot contain other tags(태그는 다른 태그를 포함 할 수 없습니다.) | 지정된 태그에는 중첩 된 태그가 없어야합니다.(The specified tag must not contain nested tags.) |
| Data limit exceeded(데이터 한도 초과) | 지정된 태그에 너무 많은 데이터가 포함되어 있습니다.(The specified tag contains too much data.) |
| Tag contains no data(태그에 데이터가 없습니다.) | 지정된 태그에 필요한 데이터가 없습니다.(The specified tag doesn’t contain necessary data.) |
| Incorrectly encoding(잘못된 인코딩) | 사이트 맵 파일이 올바른 UTF-8 접두사 (은 0xEF 0xbb 경계에서 0xBF)로 시작하지 않습니다. 다음으로 시작해야합니다.<?xml version = "1.0" encoding = "UTF-8"?>(The Sitemap file doesn’t start with the correct UTF-8 prefix (0xEF 0xBB 0xBF). It should start with the <?xml version = "1.0" encoding = "UTF-8"?>) |
| Invalid XML(잘못된 XML) | 사이트 맵 파일은 XML 구문 규칙을 준수 잘 구성된 XML 문서가 아닙니다.(The sitemap file is not a well-formed XML document complying with XML syntax rules.) |
| Too many errors (processing terminated)(오류가 너무 많음 (처리 종료 됨)) | 사이트 맵 파일 에 오류가 100 개 이상 있습니다. 파일의 추가 처리가 종료되었습니다.(There are more than 100 errors found in the sitemap file. Further processing of the file was terminated.) |
| URL limit exceeded(URL 제한 초과) | 사이트 맵 파일은 50000 개 URL을 최대를 포함 할 수 있습니다. URL을 50000 개 이상 나열해야하는 경우 사이트 맵 파일을 여러 개 만들어 색인 사이트 맵 파일 에 포함해야 합니다 ( Sitemap 색인 파일 사용 참조 ).(The sitemap file can contain a maximum of 50000 URLs. If you need to list more than 50000 URLs, you should create several sitemap files and include them in the index sitemap file (see Using Sitemap index files).) |
| Sitemap file limit exceeded(Sitemap 파일 한도를 초과했습니다.) | 사이트맵 파일의 색인 파일은 최대 50000 개의 URL을 포함 할 수 있습니다.(The Sitemap index file can contain a maximum of 50000 URLs of Sitemap files.) |
| Multiple incorrect URLs in file (processing terminated)(파일의 여러 잘못된 URL (처리 종료 됨)) | Sitemap 파일이 연속적으로 잘못된 URL로 시작됩니다. 파일의 형식이 유효하지 않을 수 있으므로 파일의 추가 처리가 종료되었습니다.(Sitemap file begins with consecutive incorrect URLs. Further processing of the file was terminated because the file is likely to have invalid format.) |
| 사이트 맵 색인 파일은 다른 링크를 포함 할 수 없습니다 사이트 맵 색인 파일을(A sitemap index file cannot contain links to other sitemap index files) | 사이트 맵 색인 파일은 참조를 포함 할 수 있습니다 사이트 맵 하지 다른 파일을 사이트 맵 색인 파일.(The Sitemap index file can only contain references to sitemapfiles, not to other sitemap index files.) |
| Error in root tag(루트 태그 오류) | 루트 태그를 처리하는 동안 오류가 발생했습니다.(An error occurred while processing the root tag.) |
사이트 맵 파일을 처리 할 때 발생하는 Warnings(경고) 목록
| Warnings(경고) | 상세 설명(Description) |
|---|---|
| Encoding not UTF-8(UTF-8이 아닌 인코딩) | UTF-8 접두사 (0xEF 0xBB 0xBF)가 없습니다.(UTF-8 prefix (0xEF 0xBB 0xBF) is missing.) |
| Unknown tag (ignored)(알 수없는 태그 (무시 됨)) | 예상치 못한 태그가 감지되었습니다. Sitemap 프로토콜 확장 일 수 있습니다 . 태그는 무시됩니다.(Unexpected tag was detected. It may be a Sitemap protocol extension. The tag is ignored.) |
| Unknown text (ignored)(알 수없는 텍스트 (무시 됨)) | 처리 중에 예기치 않은 텍스트가 감지되었습니다. 텍스트는 무시됩니다.(An unexpected text was detected during the processing. The text is ignored.) |
| Unknown attribute (ignored)(알 수없는 속성 (무시 됨)) | 처리 중에 예기치 않은 속성이 발견되었습니다. 속성이 무시됩니다.(An unexpected attribute was detected during the processing. The attribute is ignored.) |
| Too many warnings (warnings terminated)(경고가 너무 많음 (경고 종료 됨)) | 사이트 맵 파일을 처리 할 때 100 개가 넘는 경고가 생성되었습니다 . 더 이상 경고가 표시되지 않습니다.(More than 100 warning were generated when processing the sitemap file. Warning are not displayed any more.) |
| Empty line (ignored)(빈 줄 (무시 됨)) | 사이트 맵 파일을 처리 할 때 빈 줄이 감지되었습니다 .(Empty line was detected when processing the sitemap file.) |
| Incorrect URL (does not correspond to sitemap index file location)(잘못된 URL ( 사이트 맵 색인 파일 위치와 일치하지 않음 )) | 사이트 맵 색인 파일의 URL을 포함 할 수 있습니다 사이트 맵 같은 사이트에있는 파일을. 자세한 내용은 Sitemap 색인 파일 사용을 참조하세요.(The Sitemap index file can include the URLs of sitemap files located on the same site. For details, see Using Sitemap index files) |
| Invalid URL priority format(잘못된 URL 우선 순위 형식) | 우선 순위는 0.0에서 1.0 사이의 숫자 여야합니다. 자세한 내용은 XML 태그 정의를 참조하십시오.(Priority must be a number from 0.0 to 1.0. For details, see XML tag definitions.) |
| Tag must contain data(태그는 데이터를 포함해야합니다.) | 지정된 태그는 데이터를 포함해야합니다.(The specified tag must contain data.) |
| A tag cannot contain other tags(태그는 다른 태그를 포함 할 수 없습니다.) | 지정된 태그는 하위 태그를 포함 할 수 없습니다.(The specified tag cannot contain child tags.) |
| Tag data too large(태그 데이터가 너무 큼) | 지정된 태그에 너무 많은 데이터가 포함되어 있습니다.(The specified tag contains too much data.) |
| Tag contains no data(태그에 데이터가 없습니다.) | 지정된 태그에 필수 데이터가 없습니다.(Required data is missing in the specified tag.) |
Invalid lastmod tag value(잘못된 lastmod태그 값) | Lastmod태그는 잘못된 날짜가 포함되어 있습니다. 날짜는 W3C Datetime 형식 이어야 합니다.(The Lastmod tag contains an invalid date. The date must be in the the W3C Datetime format.) |
Settings
Notifications
Access rights
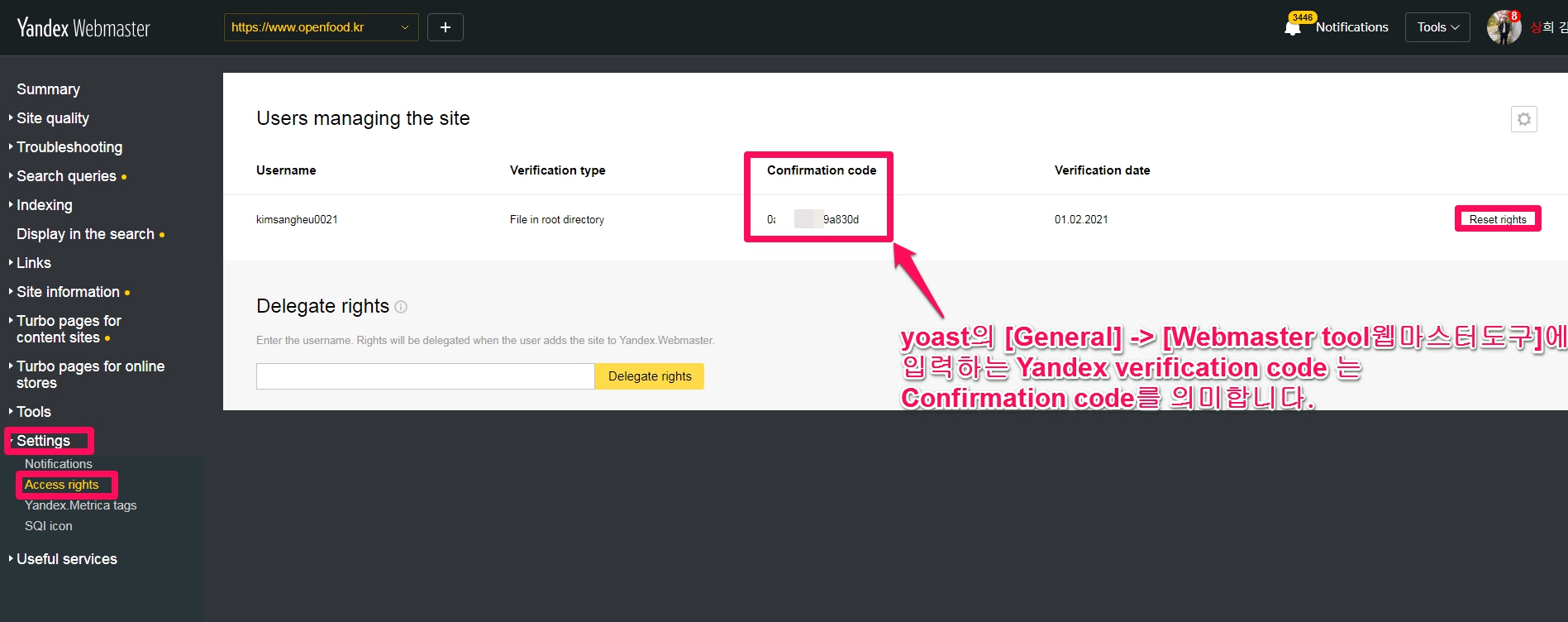
소유권 인증 여부와 어떻게 소유권을 인증했는지를 확인할 수 있습니다. ( 구글 서치콘솔처럼 다시 Meta tag을 살펴보거나 HTML file을 얻을 수는 없고 Confirmation code 정도를 얻을 수 있습니다. ) 또한 해당 사이트 관리자를 확인할 수 있습니다.
구글 웹마스터도구의 사용자 추가에 해당하는 부분인데, username을 넣는 단계에서 e-mail을 넣어주세요.
간과하지 말아야 할 것은 권한을 위임받을 사람이 yandex에 가입한 상태여야 권한 위임이 가능합니다. yandex가입은 gmail계정으로 쉽게 가입이 가능합니다.
Delegating rights(권한 위임)
After verifying the website management rights, you can transfer your rights to other Yandex.Webmaster users. The user you grant the rights to will have unrestricted access to all the service features.
(웹사이트 관리 권한을 확인한 후 다른 Yandex.Webmaster 사용자에게 권한을 양도할 수 있습니다. 권한을 부여한 사용자는 모든 서비스 기능에 제한 없이 액세스할 수 있습니다.)
To transfer the rights:(권리를 양도하려면:)
Go to the Settings → Access rights page.(설정 → 접근권 한 페이지 로 이동합니다.)
In the Delegate rights block, enter the username for the selected site.(대리인 권한 블록 에 선택한 사이트의 사용자 이름을 입력합니다.)
Click the Delegate rights button.(권한 위임 버튼을 클릭 합니다.)
The user who has been delegated rights must log in to Yandex.Webmaster under their Yandex ID and add the website. The rights are then verified automatically.
(권한을 위임받은 사용자는 Yandex ID로 Yandex.Webmaster에 로그인하여 웹사이트를 추가해야 합니다. 그러면 권한이 자동으로 확인됩니다.)
You can revoke the site management rights of another user. If you delegated the rights to another user and then your rights were revoked, this does not invalidate the rights of the other user.
(다른 사용자 의 사이트 관리 권한을 철회할 수 있습니다 . 귀하가 다른 사용자에게 권한을 위임한 후 귀하의 권한이 취소된 경우, 이는 다른 사용자의 권한을 무효화하지 않습니다.)
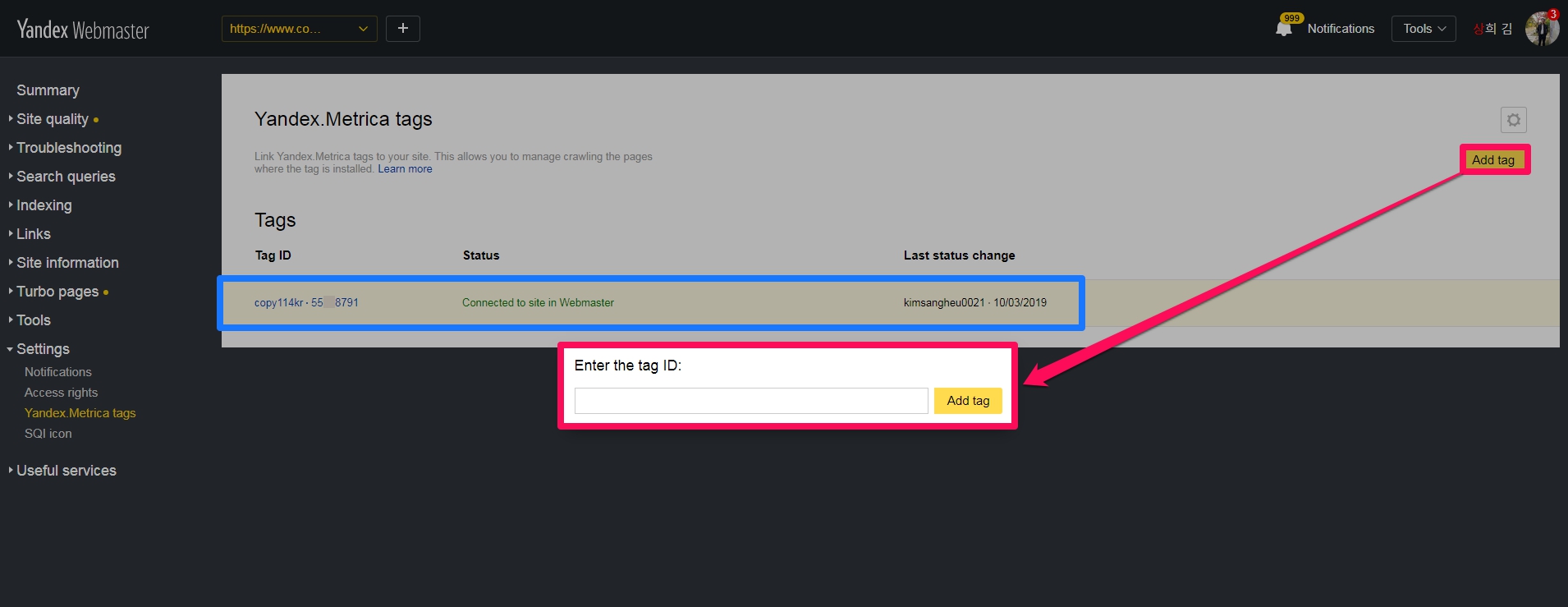
Yandex.Metrica tags
얀덱스의 분석 추적 도구인 Yandex.Metrica( https://metrica.yandex.com/list )와 연동할 수 있는 부분입니다.
Yandex.Metrica는 구글 애널리틱스와 같은 분석 도구로 Yandex가 웹 사이트 트래픽을 추적하고 보고하는 무료 웹 분석 서비스입니다. Yandex는 2008 년에 서비스를 시작했으며 2009 년에 공개했습니다. 2019 년 현재 Yandex.Metrica는 웹에서 세 번째로 널리 사용되는 웹 분석 서비스입니다.
Yandex.Metrica 태그를 사이트에 연결하십시오. 이를 통해 태그가 설치된 페이지를 크롤링 할 수 있습니다.( Link Yandex.Metrica tags to your site. This allows you to manage crawling the pages where the tag is installed. ) 얀덱스의 분석 코드를 사이트에 설치하면 더 잘 크롤링 됩니다. [Add tag]를 클릭하시면 tag ID 를 넣으라고 나옵니다. 파란색 부분은 Yandex.Metrica와 얀덱스 웹마스터가 연결된 후 상태를 보여주는 부분입니다.
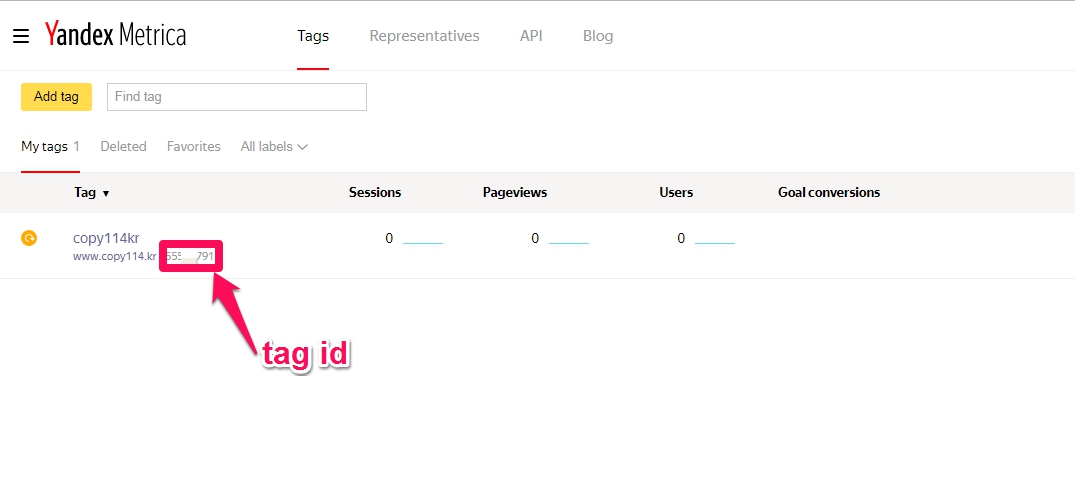
tag ID 는 Yandex.Metrica에서 확인할 수 있으며 아래의 분홍색 부분입니다.
태그를 생성하는 방법은 아래의 동영상을 따라 하시면 됩니다.
Getting started with Yandex.Metrica. Step 1: creating a tag(1:45)
더 자세한 내용은 아래의 게시글을 참조하세요.
SQI icon
Useful services
참고자료 : 1. How can I add a site to search?
3. Sitemap validator – Webmaster. Help
5. yandex support Access rights
6. Yandex Support의 Pages in search results
7. Yandex Support의 Why are pages excluded from the search?



2 Comments
[…] 얀덱스 웹마스터 도구( https://webmaster.yandex.com/ ) […]
[…] 얀덱스 웹마스터 도구( https://webmaster.yandex.com/ ) […]