- 인터넷은 우리에게 자유를 주었습니다. 저희는 자유를 얻기 위해 지식을 통합하고 체계화하고 공유합니다. 랜선 위 정글에서 살아남기 위해 저희는 시키는 일만 하는 꿀벌 대신 고객을 위해 창조하고 혁신하는 게릴라가 되겠습니다. Seenbuy.kr is now Aiforu.kr.
- 024042463
- 01032667931
- [email protected]
독창적인 나만의 최고의 AI 만들기 로드맵(KnowHow)

| 목차 |
| AI-core-strengths 머신러닝 – AI 분야에서 머신러닝이 필수적인 이유 – 소프트웨어 : 컴퓨터의 OS(운영쳬계, windows)에 해당 – 하드웨어 API : 나만의 AI를 만들어 app/web으로 서비스하기 위해 필수적임 학습할 데이터 확보 |
AI의 핵심 강점
AI는 잠재적 패턴을 찾아내고 이해하는데 탁월합니다.
어떻게 AI는 잠재적 패턴을 찾아내고 이해하는 강점을 가지게 되었을까요?
AI가 잠재적 패턴을 찾아내고 이해하는 강점은 크게 두 가지 주요 기술, 즉 기계 학습(Machine Learning, ML)과 딥 러닝(Deep Learning, DL)에 기반합니다. 이 기술들은 데이터에서 복잡한 패턴과 관계를 학습하고 예측하는 데 사용됩니다. 그 원리는 다음과 같습니다:
1. 기계 학습 (Machine Learning)
기계 학습은 알고리즘이 데이터를 분석하여 특정 작업을 수행하기 위한 패턴과 관계를 학습할 수 있도록 하는 AI의 한 분야입니다. 기계 학습 모델은 대량의 데이터를 처리하며, 그 과정에서 데이터 내의 숨겨진 패턴과 구조를 발견하고, 이를 바탕으로 예측이나 결정을 내릴 수 있습니다.
- 지도 학습(Supervised Learning): 레이블이 지정된 훈련 데이터를 사용하여 입력과 출력 사이의 관계를 학습합니다. 예를 들어, 이메일이 스팸인지 아닌지를 구분하는 모델을 훈련할 수 있습니다.
- 비지도 학습(Unsupervised Learning): 레이블이 없는 데이터를 사용하여 데이터 내의 패턴이나 구조를 발견합니다. 클러스터링(clustering)이 이에 해당합니다.
- 강화 학습(Reinforcement Learning): 시행착오를 통해 어떤 환경 내에서 최적의 결정이나 행동을 학습합니다. 이는 주로 게임이나 로봇 공학에서 사용됩니다.
2. 딥 러닝 (Deep Learning)
딥 러닝은 기계 학습의 한 분야로, 신경망(Neural Networks)이라는 알고리즘을 사용하여 인간의 뇌가 정보를 처리하는 방식을 모방합니다. 딥 러닝 모델은 여러 개의 층(layer)으로 구성되며, 각 층은 입력 데이터로부터 점점 더 복잡한 특징을 추출하고 학습합니다.
- 신경망(Neural Networks): 데이터에서 복잡한 패턴을 인식하기 위해 설계된 알고리즘입니다. 각 뉴런(neuron)은 입력 데이터로부터 특정 특징을 학습하고, 이러한 뉴런들이 모여 복잡한 함수를 모델링합니다.
- 컨볼루션 신경망(CNNs): 주로 이미지 처리에 사용되며, 이미지에서 특징을 자동으로 감지하는 데 탁월합니다.
- 순환 신경망(RNNs, Recurrent Neural Network): 시계열 데이터나 순차적 데이터 처리에 적합하며, 자연어 처리나 음성 인식에서 주로 사용됩니다.
3. 학습할 데이터의 중요성
기계 학습과 딥 러닝 모델의 성공은 대량의 고품질 데이터에 크게 의존합니다. 데이터는 알고리즘이 패턴을 학습하고, 이를 기반으로 예측이나 결정을 내리는 데 필요한 ‘경험’을 제공합니다. 모델은 데이터를 통해 끊임없이 학습하고, 새로운 데이터에 대한 예측을 개선해 나갑니다.
이러한 원리와 기술의 발전을 통해 AI는 잠재적 패턴을 찾아내고 이해하는 강점을 가지게 되고 AI가 잠재적 패턴을 찾아내고 이해하는 능력은 주로 기계 학습과 딥 러닝, 두 가지 핵심 기술에 기반을 두고 있습니다. 이 기술들은 데이터에서 복잡한 패턴을 학습하고, 이를 바탕으로 예측이나 결정을 내릴 수 있게 해줍니다. 이 과정에서 중요한 역할을 하는 것은 데이터의 양과 질, 그리고 알고리즘의 구조입니다.
작동 원리
기계 학습에서는 데이터를 분석하여 모델이 특정 작업을 수행하기 위한 패턴과 관계를 학습합니다. 이는 지도 학습, 비지도 학습, 강화 학습 등 다양한 방식으로 이루어집니다. 지도 학습에서 모델은 레이블이 지정된 데이터를 바탕으로 입력과 출력 사이의 관계를 학습하며, 비지도 학습에서는 레이블이 없는 데이터를 통해 데이터 내의 패턴이나 구조를 발견합니다. 강화 학습에서는 시행착오를 통해 최적의 결정이나 행동을 학습합니다.
딥 러닝은 기계 학습의 한 분야로, 인간의 뇌가 정보를 처리하는 방식을 모방한 신경망을 사용합니다. 딥 러닝 모델은 여러 층으로 구성되어 있으며, 각 층은 입력 데이터로부터 점점 더 복잡한 특징을 추출하고 학습합니다. 이 과정에서 컨볼루션 신경망(CNN)은 이미지 처리에, 순환 신경망(RNN)은 시계열 데이터 처리에 주로 사용됩니다.
AI가 이러한 복잡한 패턴을 학습하고 이해하는 능력은 대량의 데이터를 처리하고, 그 안에서 숨겨진 정보를 발견할 수 있는 알고리즘의 발전에 기인합니다. 데이터는 AI 시스템에 ‘경험’을 제공하며, 이 경험을 통해 시스템은 점점 더 정확한 예측을 할 수 있게 됩니다. AI 기술의 발전은 계속해서 이러한 학습 과정을 개선하고, 더 다양한 분야에서 응용할 수 있는 가능성을 열어가고 있습니다.
AI의 주요 강점(활용분야)
강점 위에 구축하라, -피터드러커-
AI로 무엇을 할 수 있는가를 연구하기 위해서는 AI가 어떤 강점을 가지고 있는지 알아야 합니다.
AI의 주요 강점은 다음과 같습니다:
- 데이터 분석과 패턴 인식 : AI는 대규모 데이터 세트에서 복잡한 패턴을 식별하고 이해하는 데 탁월합니다. 이를 통해 예측 분석, 고객 행동 분석, 재무 모델링 등 다양한 분야에서 의사결정을 지원합니다.
- 자연어 처리(Natural Language Processing, NLP) : AI는 사람의 언어를 이해하고 생성하는 능력이 뛰어납니다. 이를 통해 챗봇, 음성 인식 서비스, 감정 분석, 자동 요약 생성 등 다양한 애플리케이션을 구현할 수 있습니다.
- 이미지 및 비디오 분석: 컴퓨터 비전 기술을 활용하여 이미지와 비디오에서 객체, 얼굴, 장면을 인식하고 분석할 수 있습니다. 이는 의료 진단, 보안 감시, 자동차 운전 지원 시스템 등에 활용됩니다.
- 자율 주행 기술: AI는 센서 데이터를 분석하여 주변 환경을 인식하고, 안전한 주행 경로를 결정할 수 있는 자율 주행 차량의 핵심 기술입니다.
- 개인화 및 추천 시스템: AI는 사용자의 행동, 선호도, 구매 이력을 분석하여 맞춤형 콘텐츠, 제품 추천을 제공합니다. 이는 e커머스, 스트리밍 서비스, 소셜 미디어 플랫폼 등에서 널리 사용됩니다.
- 로봇 공학과 자동화: AI는 제조, 물류, 가정용 로봇 등에서 작업을 자동화하고 효율을 개선하는 데 기여합니다. AI 로봇은 정밀한 작업 수행, 환경 변화에 대한 적응, 독립적인 문제 해결 능력을 보입니다.
- 의료 분야 혁신: AI는 의료 영상 분석, 질병 예측 모델링, 환자 맞춤형 치료 계획 개발 등을 통해 의료 분야에서 중요한 역할을 합니다.
- 사이버 보안: AI는 사이버 위협을 식별하고 대응하는 데 사용되며, 이상 행동 감지, 침입 방지 시스템, 자동화된 보안 분석 등에서 중요한 역할을 합니다.
이러한 강점들은 AI가 다양한 산업과 분야에서 혁신을 가속화하고, 인간의 업무 부담을 줄이며, 새로운 기회를 창출하는 데 기여하고 있음을 보여줍니다. AI 기술의 발전은 계속해서 인간의 일상생활과 산업 전반에 긍정적인 변화를 가져올 것입니다.
머신러닝
AI 분야에서 머신러닝이 필수적인 이유
머신러닝은 인공지능(AI) 분야에서 핵심적인 역할을 합니다.
그 이유는 다음과 같습니다.
1. 다양한 AI 모델의 기반: 챗봇, 이미지 인식, 자연어 처리 등 대부분의 AI 모델은 머신러닝 알고리즘을 기반으로 구축됩니다. 챗GPT와 Gemini 같은 생성형 AI도 머신러닝 기술을 사용하여 학습하고 작동합니다.
2. 데이터 기반 학습: 머신러닝은 데이터를 기반으로 학습하여 스스로 성능을 개선합니다. 이는 인간이 직접 프로그래밍하는 방식보다 훨씬 효율적이고 정확한 모델을 만들 수 있게 합니다.
3. 예측 및 의사 결정: 머신러닝 모델은 학습된 데이터를 기반으로 미래를 예측하거나 최적의 의사 결정을 내릴 수 있습니다. 이는 다양한 분야에서 활용될 수 있습니다.
4. 자동화: 머신러닝은 반복적인 작업을 자동화하여 인간의 노동력을 대체할 수 있습니다. 이는 생산성을 향상시키고 비용을 절감하는 데 도움이 됩니다.
5. 새로운 발견: 머신러닝은 인간이 발견하지 못했던 새로운 패턴이나 지식을 발견하는 데 활용될 수 있습니다.
생성형 AI의 한계
데이터 의존성: 생성형 AI는 학습 데이터에 크게 의존합니다. 학습 데이터에 편향이 있거나 부족하면 생성된 결과물도 편향되거나 부정확할 수 있습니다. 해석 가능성: 생성형 AI는 작동 방식이 불투명하고 해석하기 어렵습니다. 이는 결과물에 대한 신뢰성을 떨어뜨릴 수 있습니다. 윤리적 문제: 생성형 AI는 가짜 뉴스, 혐오 발언 등 윤리적으로 문제가 있는 콘텐츠를 생성할 수 있습니다.
따라서, 생성형 AI를 안전하고 책임감 있게 사용하기 위해서는 머신러닝 기술을 더욱 발전시키고, 생성형 AI의 한계를 극복하는 연구가 필요합니다.
생성형 AI(OpenAI의 chatGPT와 Google의 Gemini기반 중심)를 활용한 지속 가능한 AI 수익화하는 방법에 관해서는 아래의 게시글을 참조하세요.
소프트웨어 : 컴퓨터의 OS(운영쳬계, windows)에 해당
머신 러닝 모델 개발 및 배포 플랫폼=AI 개발 및 배포
chatGPT와 같은 초거대기업이 제공하는 생성형 AI가 아닌 나만의 AI 개발 및 배포는 머신 러닝 모델 개발 및 배포와 동의어라고 보시면 됩니다.
개발은 Gemini Advanced(Gemini Ultra 1.0) / VertexAi /TensorFlow 로 하고 배포는 Google AI Studio와 Vertex AI Studio로 합니다.
참고로 chatGPT에서는 assitant와 GPTs가 여기에 해당합니다.
개발 : Gemini Advanced(Gemini Ultra 1.0) / VertexAi / TensorFlow
머신 러닝 모델 개발 및 배포 플랫폼 선택 가이드
머신 러닝 모델 개발 및 배포 플랫폼은 다양하며, 각 플랫폼마다 장단점이 있습니다. Gemini Advanced (Gemini Ultra 1.0), Vertex AI, TensorFlow 세 가지 플랫폼의 주요 특징과 장단점을 비교하여 상황에 맞는 최적의 플랫폼을 선택하는 데 도움을 드리겠습니다.
1. Gemini Advanced (Gemini Ultra 1.0)
특징:
- 대규모 모델 학습 및 배포에 특화: 100억 개 이상의 파라미터를 가진 대규모 모델 학습 및 배포에 최적화
- 높은 성능 및 확장성: TPUv4 칩 기반, 1000 PFLOPS 이상의 성능 제공, 수천 개의 TPUv4 칩으로 확장 가능
- 사용 편의성: 직관적인 UI, 자동화 기능 제공
- 높은 비용: 다른 플랫폼 대비 비용이 높음
- 제한적인 접근성: 현재 제한된 파트너에게만 제공
- MOE(Mixture Of Expert) 채택으로 성능향상
- 입력토큰수 100만개로 파인튜닝 필요없음 : 입력토큰 수 100 만개는 1시간 분량의 비디오, 11시간 분량의 오디오,ㅡ300만줄의 코드, 70만 단어, 책 10권을 입력할 수 있는 분량입니다. GPT4의 경우, 128,000토큰으로 Gemini Advanced (Gemini Ultra 1.0)의 1/10 수준임.
장점:
대규모 모델 학습 및 배포에 최적화 높은 성능 및 확장성 제공 사용 편의성
단점:
높은 비용 제한적인 접근성
Gemini Advanced와 VertexAI 공통점과 차이점
| 구분 | Gemini Advanced | Vertex AI |
| 대상 유저 | 숙련된 머신 러닝 전문가 | 다양한 경험 수준의 머신 러닝 사용자 |
| 사용 편의성 | 상대적으로 낮음 | 상대적으로 높음 |
| 자동화 기능 | 제한적 | 풍부함 |
| 모델 관리 기능 | 기본적 | 고급 |
| 비용 | 사용량 기반 | 요금제 기반 |
2. Vertex AI
특징:
종합적인 머신 러닝 플랫폼: 데이터 전처리, 모델 학습, 모델 평가, 모델 배포, 모델 모니터링까지 종합적인 기능 제공 다양한 모델 지원: 딥 러닝, 강화 학습, 베이지안 모델 등 다양한 모델 지원 다양한 하드웨어 지원: CPU, GPU, TPU 등 다양한 하드웨어 플랫폼에서 실행 가능 관리형 서비스: 인프라 관리 및 유지보수 없이 바로 사용 가능 비교적 높은 비용: TensorFlow 대비 비용이 높음
장점:
종합적인 머신 러닝 플랫폼 다양한 모델 및 하드웨어 지원 관리형 서비스
단점:
비교적 높은 비용
결론
각 플랫폼마다 장단점이 있으며, 최적의 플랫폼은 사용자의 상황에 따라 다릅니다. 위의 정보를 참고하여 상황에 맞는 플랫폼을 선택하시길 바랍니다.
Vertex AI 관련 자료는 아래의 게시글이 기본적으로 정리해주세요.
3. TensorFlow
특징:
오픈 소스 플랫폼: 누구나 무료로 사용 가능 유연성: 다양한 프로그래밍 언어 지원, 사용자 정의가 용이 활발한 커뮤니티: 다양한 학습 자료 및 지원 제공 높은 기술 숙련도 요구: 직접 코드 작성 및 인프라 관리 필요
장점:
무료 유연성 활발한 커뮤니티
단점:
높은 기술 숙련도 요구
선택 가이드
대규모 모델 학습 및 배포: Gemini Advanced (Gemini Ultra 1.0) 종합적인 머신 러닝 플랫폼: Vertex AI 유연성 및 커뮤니티 지원: TensorFlow 낮은 비용: TensorFlow 높은 기술 숙련도: TensorFlow 관리형 서비스: Vertex AI
추가 고려 사항
사용 목적: 모델 개발, 연구, 프로덕션 환경 배포 등 데이터 크기 및 모델 종류: 모델 학습 및 배포에 필요한 리소스 기술 숙련도: 플랫폼 사용 및 관리에 필요한 기술 수준 예산: 플랫폼 사용 비용
AI 개발 및 배포 플랫폼 선택 가이드: Gemini Advanced, Vertex AI, TensorFlow 비교
머신 러닝 모델 개발 및 배포 플랫폼 선택은 중요한 결정입니다. 각 플랫폼마다 장단점이 있으며, 상황에 맞는 최적의 플랫폼을 선택해야 효율적인 AI 개발 및 배포가 가능합니다. Gemini Advanced (Gemini Ultra 1.0), Vertex AI, TensorFlow 세 가지 플랫폼을 비교하여 선택에 도움을 드리겠습니다.
1. 플랫폼 비교
| 플랫폼 | 특징 | 장점 | 단점 |
| Gemini Advanced (Gemini Ultra 1.0) | – 대규모 모델 학습 및 배포에 특화 (100억+ 파라미터) – 높은 성능 및 확장성 (TPUv4 기반, 1000+ PFLOPS) – 사용 편의성 (직관적인 UI, 자동화 기능) | – 높은 비용 – 제한적인 접근성 (현재 제한된 파트너에게만 제공) | – 대규모 모델 개발 및 배포에 적합 – 높은 성능 및 확장성 요구 – 사용 편의성 중요 |
| Vertex AI | – 종합적인 머신 러닝 플랫폼 (데이터 전처리, 모델 학습, 평가, 배포, 모니터링) – 다양한 모델 지원 (딥 러닝, 강화 학습, 베이지안 모델 등) – 다양한 하드웨어 지원 (CPU, GPU, TPU) – 관리형 서비스 (인프라 관리 및 유지보수 없이 바로 사용 가능) | – 비교적 높은 비용 | – 종합적인 머신 러닝 플랫폼 필요 – 다양한 모델 및 하드웨어 지원 필요 – 관리형 서비스 선호 |
| TensorFlow | – 오픈 소스 플랫폼 (무료) – 유연성 (다양한 프로그래밍 언어 지원, 사용자 정의 용이) – 활발한 커뮤니티 (다양한 학습 자료 및 지원 제공) | – 높은 기술 숙련도 요구 (직접 코드 작성 및 인프라 관리 필요) | – 유연성 및 커뮤니티 지원 중요 – 기술 숙련도 높음 – 비용 절감 중요 |
2. 선택 가이드
- 대규모 모델 개발 및 배포: Gemini Advanced (Gemini Ultra 1.0)
- 종합적인 머신 러닝 플랫폼: Vertex AI
- 유연성 및 커뮤니티 지원: TensorFlow
- 낮은 비용: TensorFlow
- 높은 기술 숙련도: TensorFlow
- 관리형 서비스: Vertex AI
3. 추가 고려 사항
- 사용 목적: 모델 개발, 연구, 프로덕션 환경 배포 등
- 데이터 크기 및 모델 종류: 모델 학습 및 배포에 필요한 리소스
- 기술 숙련도: 플랫폼 사용 및 관리에 필요한 기술 수준
- 예산: 플랫폼 사용 비용
4. 결론
각 플랫폼마다 장단점이 있으며, 최적의 플랫폼은 사용자의 상황에 따라 다릅니다. 위의 정보를 참고하여 상황에 맞는 플랫폼을 선택하시길 바랍니다.
배포
Google AI Studio와 Vertex AI Studio 비교
Google AI Studio와 Vertex AI Studio는 모두 Google Cloud Platform (GCP)에서 제공하는 머신 러닝 (ML) 모델 개발 및 배포를 위한 플랫폼입니다. 하지만 두 플랫폼은 다음과 같은 주요 차이점을 가지고 있습니다.
| 항목 | Google AI Studio | Vertex AI Studio |
| 대상 사용자 | 초보 ML 개발자, 코드 작성 경험 적거나 없음 | 경험이 풍부한 ML 개발자, 코드 작성 경험 있음 |
| 기능 | 템플릿 기반 모델 개발, 데이터 전처리/평가, 배포 (Vertex AI Pipelines, AI Platform Prediction) | Jupyter Notebooks/Python 스크립팅, 고급 데이터 전처리/평가, 배포 (Vertex AI Pipelines, AI Platform Prediction, Kubeflow Pipelines) |
| 가격 | 무료 | 사용량 기반 과금 |
| 적합한 경우 | 간편한 모델 개발, 코드 작성 경험 없음, 무료 | 유연하고 세밀한 모델 개발, 코드 작성 경험 있음, 유료 |
| 데이터 과학 지식 수준 | 초급 | 중급/고급 |
| 코드 작성 경험 | 적거나 없음 | 필요 |
| 사용 편의성 | 높음 | 낮음 |
| 유연성 | 낮음 | 높음 |
| 기능 | 기본 | 고급 |
| 배포 옵션 | Vertex AI Pipelines, AI Platform Prediction | Vertex AI Pipelines, AI Platform Prediction, Kubeflow Pipelines |
| 모델 템플릿 | 제공 | 제공하지 않음 |
| 커뮤니티 지원 | 활발 | 활발 |
1. 대상 사용자
Google AI Studio: 초보 ML 개발자 및 데이터 과학자 코드 작성 경험이 적거나 없는 사용자 드래그 앤 드롭 방식의 UI를 사용하여 모델을 쉽게 구축 및 배포
Vertex AI Studio: 경험이 풍부한 ML 개발자 및 데이터 과학자 코드 작성 경험이 있는 사용자 Jupyter Notebooks 및 Python 스크립팅을 사용하여 모델을 개발 및 배포
2. 기능
Google AI Studio: 템플릿 기반 모델 개발: 다양한 사전 훈련된 모델 템플릿을 사용하여 빠르게 모델을 구축 데이터 전처리 및 모델 평가 기능 제공 배포 옵션: Vertex AI Pipelines, AI Platform Prediction
Vertex AI Studio: 더 많은 유연성 및 제어: Jupyter Notebooks 및 Python 스크립팅을 사용하여 모델을 자유롭게 개발 고급 데이터 전처리 및 모델 평가 기능 제공 배포 옵션: Vertex AI Pipelines, AI Platform Prediction, Kubeflow Pipelines
3. 가격
Google AI Studio: 무료
Vertex AI Studio: 사용량 기반 과금
4. 선택 가이드
- 초보 ML 개발자: Google AI Studio
- 경험이 풍부한 ML 개발자: Vertex AI Studio
- 코드 작성 경험 없음: Google AI Studio
- 코드 작성 경험 있음: Vertex AI Studio
- 간편한 모델 개발: Google AI Studio
- 유연하고 세밀한 모델 개발: Vertex AI Studio
- 무료: Google AI Studio
- 유료: Vertex AI Studio
결론
Google AI Studio와 Vertex AI Studio는 모두 GCP에서 제공하는 ML 모델 개발 및 배포 플랫폼입니다. 사용자의 경험 수준, 기능 요구 사항, 예산 등을 고려하여 적합한 플랫폼을 선택해야 합니다.
CUDA(“Compute Unified Device Architecture”, 쿠다)
CUDA는 머신 러닝 모델 개발 및 배포 플랫폼은 아님. 스마트폰등 전자제품에 on Device구현 가능합니다. (예 : SKT의 통역 통화서비스).
GPGPU(General-Purpose computing on Graphics Processing Units, GPU 상의 범용 계산)
그래픽 처리 장치(GPU)에서 수행하는 (병렬 처리) 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술이다.
NVIDIA 는 GPU 또는 칩회사이면서 쿠다 즉, GPU 운영회사이며 AI 개발회사입니다.
CUDA는 머신 러닝 모델 개발 및 배포 플랫폼은 아니지만, 모델 학습 및 추론 속도를 크게 높일 수 있는 강력한 도구입니다. GPU를 활용하여 머신 러닝 모델의 성능을 향상시키고 싶다면 CUDA를 활용하는 것을 고려해 볼 수 있습니다.
하드웨어
딥 러닝 모델 학습 및 추론 작업에 특화된 처리 장치 : 컴퓨터의 CPU에 해당함.
TPU(Tensor Porecess Unit)
텐서 처리 장치는 구글에서 2016년 5월에 발표한 데이터 분석 및 딥러닝용 하드웨어이다.
NVIDIA의 GPU에 밀렸지만 여전히 딥 러닝 모델 학습 및 추론 작업에 특화된 처리 장치 No2임.
GPU
NVIDIA
TPU와 GPGPU의 공통점과 차이점
공통점
- 딥 러닝 작업에 특화: TPU와 GPGPU는 모두 딥 러닝 모델 학습 및 추론 작업에 특화된 처리 장치입니다.
- 병렬 처리: 두 장치 모두 대규모 행렬 계산을 빠르게 처리하기 위해 병렬 처리 능력을 활용합니다.
- 높은 성능: CPU에 비해 압도적으로 높은 성능을 제공하며, 딥 러닝 작업 시간을 크게 단축할 수 있습니다.
차이점
| 구분 | TPU | GPGPU |
| 정의 | Tensor Processing Unit | General-Purpose GPU |
| 개발 | NVIDIA, AMD 등 | |
| 최적화 | 딥 러닝 | 다양한 작업 |
| 병렬 처리 능력 | 높음 | 상대적으로 낮음 |
| 전력 효율성 | 높음 | 상대적으로 낮음 |
| 비용 | 높음 | 상대적으로 낮음 |
| 사용 편의성 | 낮음 | 높음 |
세부적인 차이점
- 최적화: TPU는 딥 러닝 작업에 최적화되어 딥 러닝 모델 학습 및 추론 속도가 GPGPU보다 빠릅니다.
- 병렬 처리 능력: TPU는 GPGPU보다 더 많은 병렬 처리 능력을 제공하며, 특히 행렬 곱셈 연산에 효율적입니다.
- 전력 효율성: TPU는 GPGPU보다 전력 효율성이 높아 에너지 소비를 줄일 수 있습니다. 비용: TPU는 GPGPU보다 비용이 높습니다.
- 사용 편의성: TPU는 GPGPU보다 사용 편의성이 낮으며, 딥 러닝 프레임워크와의 통합도 상대적으로 어렵습니다.
결론
TPU와 GPGPU는 딥 러닝 작업에 사용되는 고성능 처리 장치이지만, 각각 장단점이 있습니다. 딥 러닝 작업 속도를 최우선으로 고려한다면 TPU가 더 적합하며, 비용과 사용 편의성을 고려한다면 GPGPU가 더 적합할 수 있습니다.
거대한 메모리 : 컴퓨터의 메모리에 해당함.
Google One(2Tbyte)
컴퓨터의 메모리에 해당합니다. Gemini Advanced(Gemini Ultra 1.0) 유료로 이용하면 2Tbyte 용량을 이용할 수 있습니다. (정확히는 Google One(2Tbyte) 유료 이용 고객은 Gemini Advanced(Gemini Ultra 1.0) 유료버전을 이용할 수 있습니다. 구글 자사의 클라우드 고객에게 생성형 AI인 Gemini Advanced(Gemini Ultra 1.0) 서비스를 무료 제공합니다. )
PDF, DOC, Gmail은 확장프로그램으로 연결하여 자동으로 Gemini Advanced(Gemini Ultra 1.0) AI와 연동됩니다. 여기에 자료를 PDF로 올리면 이것만으로도 완벽한 지식베이스(데이터 센터)가 됩니다.
머신러닝 모델 구축에 필요한 메모리 용량은 모델의 종류, 데이터 크기, 학습 방식 등 여러 요인에 따라 달라집니다.
일반적으로 다음과 같은 경우 거대한 메모리가 필요합니다.
1. 대규모 데이터 학습: 이미지, 텍스트, 음성과 같은 고차원 데이터는 많은 메모리 공간을 차지합니다. 특히, 대규모 데이터 세트를 학습하는 경우에는 더 많은 메모리가 필요합니다.
2. 딥러닝 모델 학습: 딥러닝 모델은 수백만 개 또는 수십억 개의 파라미터를 가지고 있어 모델 자체가 매우 크기 때문에 많은 메모리 공간이 필요합니다.
3. 배치 처리: 머신러닝 모델은 학습 과정에서 여러 데이터 샘플을 동시에 처리하여 속도를 높일 수 있습니다. 이를 배치 처리라고 합니다. 배치 처리를 위해서는 여러 데이터 샘플을 메모리에 저장해야 하기 때문에 많은 메모리 공간이 필요합니다.
4. 중간 결과 저장: 머신러닝 모델 학습 과정에서 중간 결과를 저장해야 하는 경우도 있습니다. 예를 들어, 딥러닝 모델 학습 과정에서 백프로파게이션 알고리즘을 사용하는 경우, 각 레이어의 출력값을 중간 결과로 저장해야 합니다. 이러한 중간 결과 또한 많은 메모리 공간을 차지합니다.
5. 분산 학습: 대규모 데이터를 학습하기 위해 여러 컴퓨터에서 분산 학습을 하는 경우, 각 컴퓨터는 전체 데이터의 일부를 메모리에 저장해야 합니다.
6. 실시간 학습: 실시간으로 데이터를 학습하고 예측하는 경우, 새롭게 들어오는 데이터를 메모리에 저장해야 합니다.
하지만, 모든 머신러닝 모델이 거대한 메모리를 필요로 하는 것은 아닙니다.
다음과 같은 경우에는 비교적 적은 메모리로도 모델을 구축할 수 있습니다.
1. 소규모 데이터 학습: 센서 데이터와 같은 저차원 데이터는 많은 메모리 공간을 차지하지 않습니다.
2. 단순 모델 학습: 선형 회귀 모델과 같은 단순 모델은 많은 파라미터를 가지고 있지 않기 때문에 많은 메모리 공간이 필요하지 않습니다.
3. 온라인 학습: 온라인 학습 방식은 데이터를 한 번에 처리하기 때문에 배치 처리에 비해 적은 메모리 공간이 필요합니다.
결론 : 머신러닝 모델 구축에 필요한 메모리 용량은 모델의 종류, 데이터 크기, 학습 방식 등 여러 요인에 따라 달라집니다. 따라서, 모델 구축 전에 메모리 용량 요구 사항을 carefully 고려해야 합니다.
API : 나만의 AI를 만들어 app/web으로 서비스하기 위해 필수적임
학습할 데이터 확보
위에 AI의 핵심 강점중 3. 데이터의 중요성에서 데이터의 중요성에 관해서는 설명하였습니다.
위에서 언급한 AI 개발 및 배포, API, 웹/앱 개발(코딩)은 시간을 투자하여 학습을 하면 모두 가능하나 데이터의 확보는 어려움이 많습니다. 그것은 양질의 데이터(CCTV 영상, Xray 영상, 제품 PCB영상 등)는 조직의 내부에 있기 때문에 외부의 개발자는 접근하기 어렸기 때문입니다.
이런 이유로 학습할 데이터의 확보는 AI개발에 있어 중요한 과업이 됩니다.
조직 내부에 있는 양질의 데이터들(CCTV 영상, Xray 영상, 제품 PCB영상 등)을 확보할 수 없는 상황에서 웹으로 접근할 수 있는 데이터에는 공공데이터, pdf 논문, 판례, 특허 공고, 전자공시시스템 등이 있습니다. 웹으로 접근할 수 있는 데이터를 기반으로 AI 개발 및 배포, API, 웹/앱 개발(코딩)을 숙달하시고 이후 조직 내부의 데이터를 기반으로 AI 개발 및 배포, API, 웹/앱 개발(코딩)을 해보세요.
AI 허브
한국지능정보사회진흥원(NIA)이 운영하는 AI 통합 플랫폼입니다.
한국지능정보사회진흥원(National Information society Agency, NIA)은 대한민국 국가기관의 정보화 추진과 관련된 정책을 개발하고, 정보문화 조성, 정보격차 해소 등을 지원하려는 목적으로 만들어진 대한민국 과학기술정보통신부 산하 위탁집행형 준정부기관이다.(출처 : 위키백과)
데이터 찾기
헬스케어 등에 조직 내부에 있는 조직 내부에 있는 양질의 데이터들(CCTV 영상, Xray 영상, 제품 PCB영상 등)에 해당하는 데이터 세트들이 있습니다. 그 품질을 다시 한번 확인해주세요.
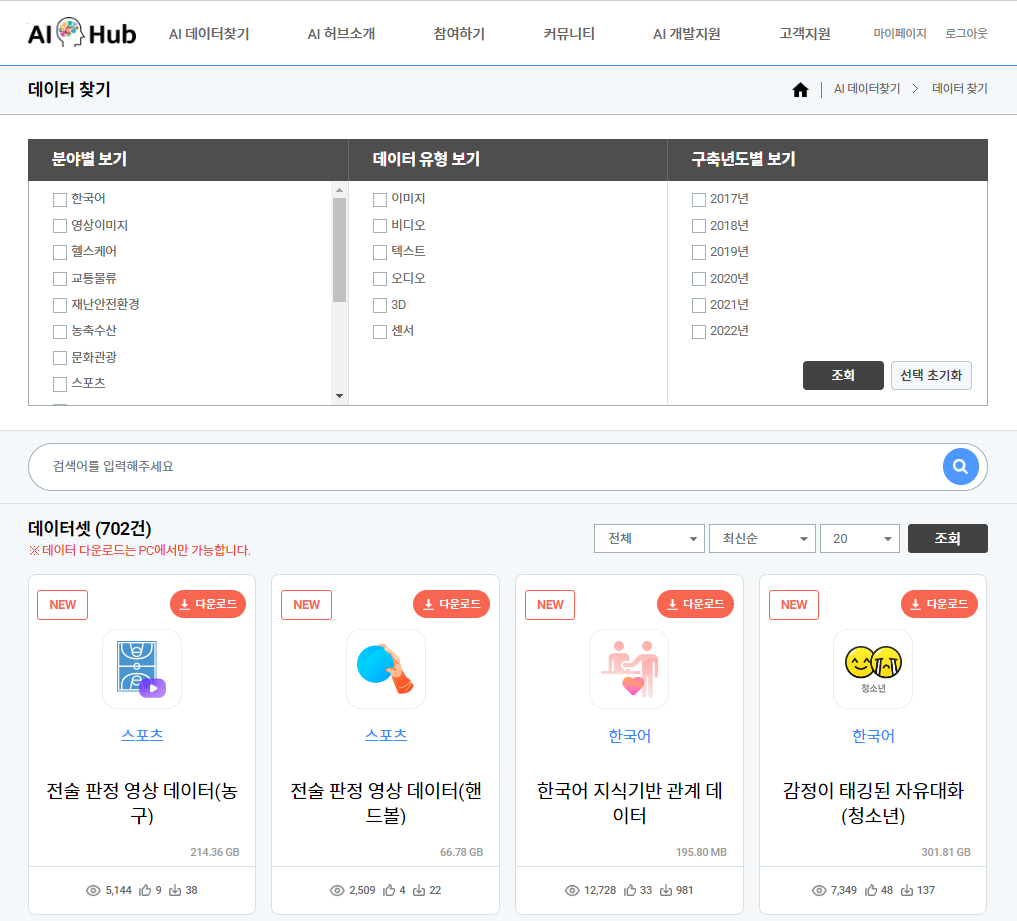
교육정보
79개의 동영상 자료가 있습니다.
유튜브 채널 주소는 https://www.youtube.com/channel/UCmMgn0-i7HfHNsxUYANXclw 입니다.
활용 및 우수사례
[memo]활용 및 우수사례를 살펴보고 아래의 게시글에 추가해주세요.
AI 개발해 볼만한 데이터 세트
평소에 관심이 있었고 개인적으로 도전해 볼만한 데이터 세트로는 아래와 같은 것이 있습니다.
음식 이미지 및 영양정보 텍스트
https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=74
분야 : 영상이미지, 유형: 이미지
- 소개 : 음식 분류를 위한 음식종류 및 양에 따른 칼로리, 염분, 당도 등 학습용 데이터
- 구축 목적 : 한국인 다빈도 섭취 외식메뉴와 한식메뉴 400종을 선정하여 양질의 이미지데이터를 수집, 구축하고 이를 기반으로 음식의 종류와 양을 추정할 수 있는 알고리즘을 개발하기 위한 데이터셋
반려견, 반려묘 건강정보 데이터
분야 : 농축수산, 유형 : 이미지
- 소개 : 반려견, 반려묘 건강정보와 관련된 데이터를 확보하고, 건강 상태 서비스 및 활력 데이터를 이용한 인공지능 데이터 활용 응용모델 개발
- 구축목적 : 크라우드소싱 데이터 수집 플랫폼 구축 및 데이터 품질검증을 통한 인공지능 서비스 개발에 필요한 반려견, 반려묘 건강정보 학습용 데이터 구축 반려동물의 표준 데이터베이스를 통한 건강상태 및 사양관리 등과 품종별 호발질병을 분석하는 인공지능 개발을 위한 데이터 구축
AI 개발지원
AI 컴퓨팅 지원, AI S/W 지원 을 하는데, google 상품들과 비교할 필요가 있습니다. 구글의 모델가든과 비교해 볼 때, AI 모델들이 좀 생소한 것 같습니다.
Kaggle(24.3.26 기준, 307,744 개)
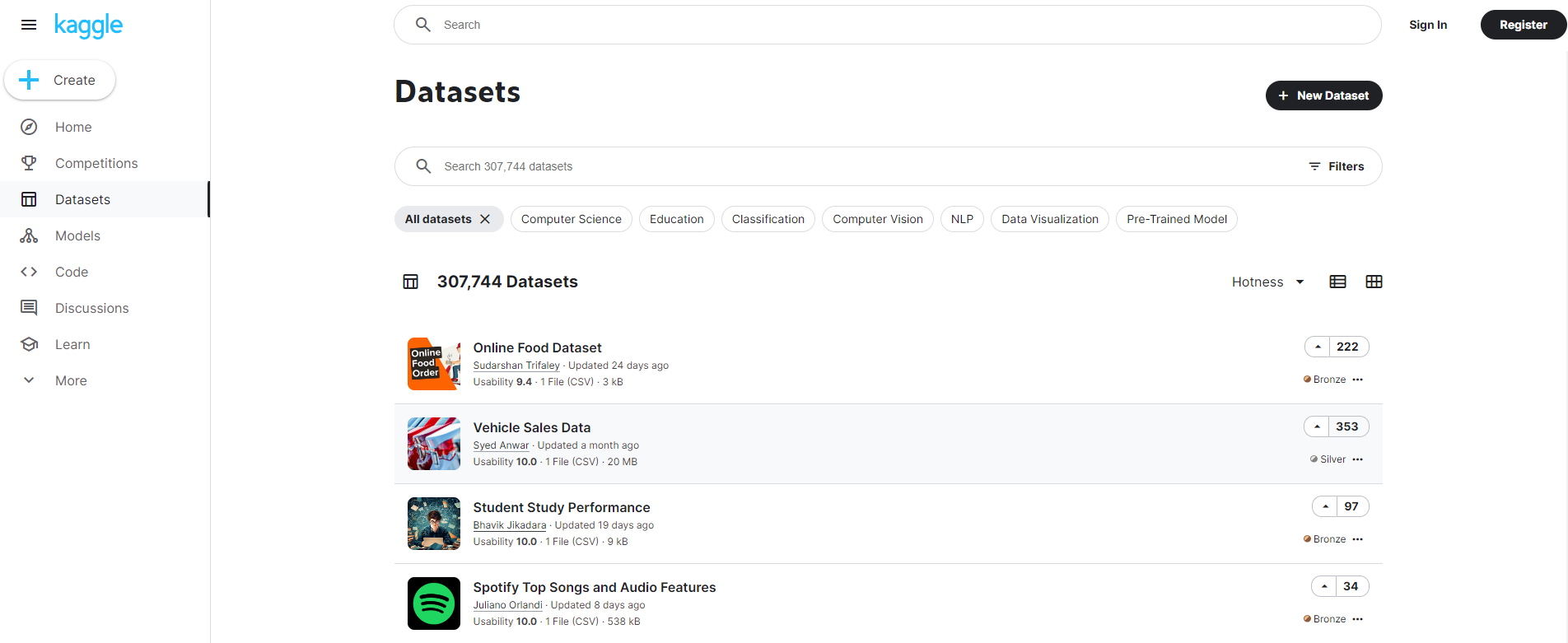
Kaggle은 머신 러닝과 데이터 과학을 위한 플랫폼입니다. 다른 데이터 과학자 및 ML 애호가와 연결하고 프로젝트를 공동 작업할 수 있는 커뮤니티 포럼을 제공합니다. Kaggle은 또한 공개 데이터 세트, 사전 훈련된 모델 및 코드 노트북에 대한 액세스를 제공합니다. 사용자는 ML 기술을 테스트하고 향상시키기 위해 대회에 참여할 수 있습니다.
Kaggle은 머신 러닝 커뮤니티에서 가장 인기 있는 플랫폼 중 하나입니다. 전 세계의 데이터 과학자와 ML 애호가들이 Kaggle을 사용하여 데이터를 분석하고 모델을 훈련하고 새로운 기술을 배웁니다.
Kaggle의 주요 기능은 다음과 같습니다.
- 커뮤니티 포럼: 다른 데이터 과학자 및 ML 애호가와 연결하고 프로젝트를 공동 작업할 수 있습니다.
- 공개 데이터 세트: 머신 러닝 모델을 훈련하는 데 사용할 수 있는 다양한 데이터 세트에 액세스할 수 있습니다.
- 사전 훈련된 모델: 머신 러닝 모델을 빠르게 훈련하는 데 사용할 수 있는 사전 훈련된 모델에 액세스할 수 있습니다.
- 코드 노트북: 머신 러닝 모델을 훈련하고 평가하는 데 사용할 수 있는 코드 노트북에 액세스할 수 있습니다.
- 대회: ML 기술을 테스트하고 향상시키기 위해 대회에 참여할 수 있습니다.
Kaggle은 머신 러닝을 배우고자 하는 사람에게 훌륭한 리소스입니다. Kaggle을 사용하여 데이터를 분석하고 모델을 훈련하고 새로운 기술을 배울 수 있습니다.
아래의 2개의 게시글을 더 살펴보세요. 대단히 흥미롭고 ML학습의 공간으로도 많이 추천받고 있습니다.
Google Vertex AI로 신용카드 이상탐지 AutoML 모델 만들기
Kaggle : All you need to know about this platform
UCI Machine Learning Repository( 2023년 12월 기준, 총 616개 )
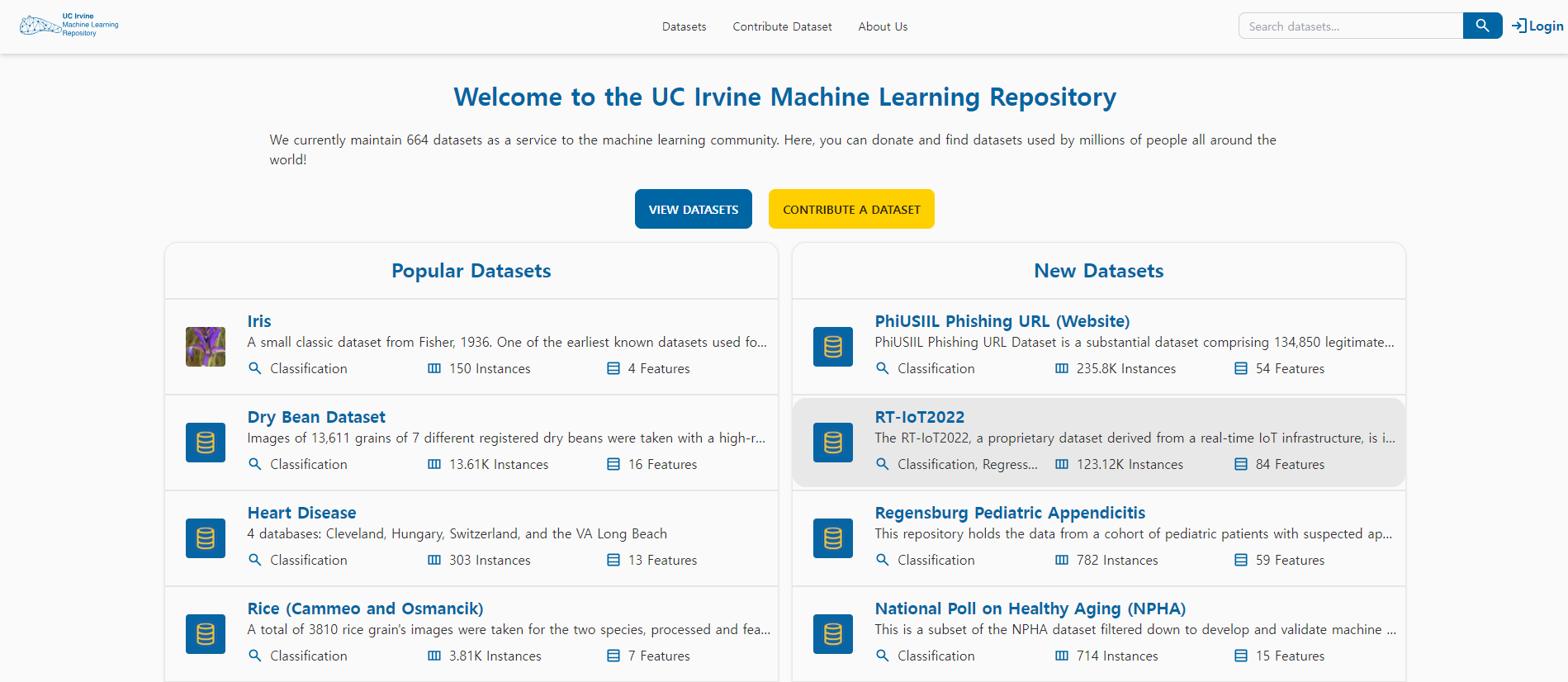
UCI Machine Learning Repository는 머신 러닝 알고리즘 개발 및 평가에 널리 사용되는 대표적인 공개 데이터 세트 저장소입니다. 2023년 12월 기준, 총 616개의 데이터 세트를 보유하고 있으며, 각 데이터 세트는 다양한 주제, 크기, 어려움 수준을 가지고 있습니다.
데이터 세트 수준:
- 초급: 머신 러닝 입문자에게 적합한 작고 간단한 데이터 세트입니다. 예를 들어, Iris 데이터 세트는 3가지 종류의 홍채 꽃에 대한 150개의 관측치를 포함합니다.
- 중급: 머신 러닝에 대한 기본적인 이해가 있는 사용자에게 적합한 크기와 어려움 수준의 데이터 세트입니다. 예를 들어, 와인 데이터 세트는 3가지 종류의 와인에 대한 178개의 관측치를 포함합니다.
- 고급: 숙련된 머신 러닝 사용자에게 적합한 크고 복잡한 데이터 세트입니다. 예를 들어, MNIST 데이터 세트는 60,000개의 훈련 이미지와 10,000개의 테스트 이미지를 포함하는 손글씨 숫자 데이터 세트입니다.
데이터 세트 유형:
- 분류: 데이터 포인트를 여러 개의 카테고리 중 하나로 분류하는 작업에 사용되는 데이터 세트입니다. 예를 들어, 와인 데이터 세트는 와인 종류를 분류하는 데 사용될 수 있습니다.
- 회귀: 연속적인 값을 예측하는 작업에 사용되는 데이터 세트입니다. 예를 들어, 보스턴 주택 가격 데이터 세트는 주택 가격을 예측하는 데 사용될 수 있습니다.
- 클러스터링: 유사한 특성을 가진 데이터 포인트를 그룹화하는 데 사용되는 데이터 세트입니다. 예를 들어, 고객 데이터 세트는 고객을 그룹으로 나누는 데 사용될 수 있습니다.
데이터 세트 활용:
- 머신 러닝 알고리즘 개발 및 평가: 새로운 알고리즘을 개발하거나 기존 알고리즘의 성능을 평가하는 데 사용할 수 있습니다.
- 머신 러닝 교육 및 튜토리얼: 머신 러닝 개념을 배우고 다양한 알고리즘을 실습하는 데 사용할 수 있습니다.
- 데이터 과학 연구: 다양한 분야의 데이터 분석 및 모델링에 사용할 수 있습니다.
UCI Machine Learning Repository는 머신 러닝 분야에 중요한 역할을 하고 있으며, 다양한 데이터 세트를 제공함으로써 연구, 교육, 개발에 기여하고 있습니다.
공공데이터
기미나인(https://gimi9.com/)
오픈데이터(공공데이터 + 민간데이터) 검색 서비스. 이 게시글을 작성하는 24년 3월 22일 기준, 2021년 1월부터 최근 2024년 2월까지 꾸준히 업데이트하고 있는 대단히 훌륭한 오픈데이터(공공데이터 + 민간데이터) 검색 포털입니다. 추천도 하고 저도 많이 이용할 것 같습니다. 기미나인, 겸손의 미덕을 기본으로 가지고 있는 존경스러운 포털입니다.
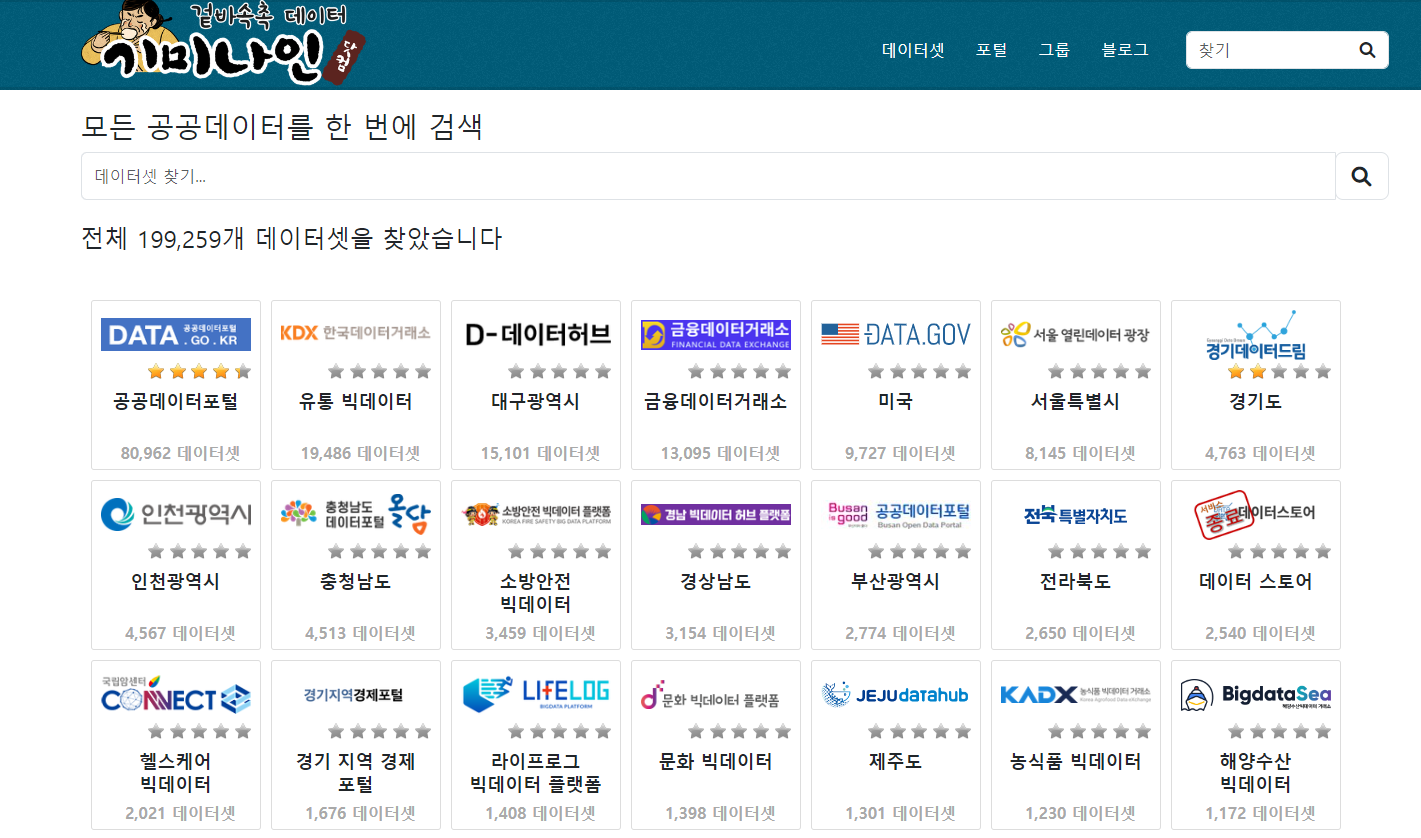
공공데이터를 활용하면 정부는 다양한 분야에서 발생하는 데이터를 수집하여 이를 분석하고 공유함으로써 효율적이고 효과적인 정책을 수립할 수 있습니다. 예를 들어, 교통, 보건, 환경 등 다양한 분야의 데이터를 종합적으로 활용하여 도시 계획, 의료 정책, 환경 보호 정책 등을 개선하고 발전시킬 수 있습니다.
민간 기업은 이러한 데이터를 기반으로 새로운 비즈니스 모델을 창출하고 혁신적인 서비스를 제공할 수 있습니다. 데이터를 기반으로 한 스마트 시티 기술, 빅데이터 분석을 활용한 서비스 등이 그 대표적인 사례입니다. (출처 : 기미나인은? )
기미나인의 노력 (주요 기능)
- 모든 공공/민간 데이터를 한 번에 검색
- 데이터 미리보기, 위치 정보(지도), Profile Report 등 부가 정보 제공
- CKAN 기반의 데이터 개방 표준을 보장
- 웹표준 준수, 모바일웹 지원
- 대표적인 EDA 리포트인 Pandas profile 제공
검색
- 타이틀, 설명, 태그, URL 검색
- 정렬:
- 관련성
- 이름 오름차순
- 이름 내림차순
- 최근 업데이트순
- 품질순 (예정)
- 사용자의 평가(별점) 순 (예정)
필터링
기관
분류
- 지도 : 지도라고 표시된 자료에는 경위도 좌표값이 있어 구글지도, 네이버지도에 표시할 수 있습니다.
- API
- 빅데이터
- AI
태그
더 많은 태그 - 포맷 : CSV, HTML, API, 지도, ZIP, XLSX, PDF, LINK, JSON, API 별로 조회할 수 있습니다.
- 라이선스
- 가격
사이트는 Wagtail(the leading open-source Python CMS)으로 만들었으며 CKAN으로 데이터를 관리하는 것 같습니다. Wagtail CMS를 이용하는 10위안의 사이트들은 blog.google, about.google, deepmind.google, flutter.dev, grow.google, blog.youtube, sendgrid.com, commandprompt.com, anydebrid.com, gandi.net으로 대단한 CMS입니다. 저 같은 하수는 CMS로 워드프레스를 활용하고 고수들은 Wagtail 를 이용한다는 점에서도 Wagtail 는 매우 흥미롭습니다.
참고로 CKAN( https://ckan.org/ )은 데이터 허브 및 데이터 포털을 구동하기 위한 오픈 소스 DMS(데이터 관리 시스템)입니다. CKAN을 사용하면 데이터 게시, 공유 및 사용이 쉬워집니다. 이는 전 세계적으로 수백 개의 데이터 포털을 지원합니다. 파이썬
파이썬  4.2k
4.2k  190만
190만
기미나인(https://gimi9.com/)은 공공 데이터에 대한 접근을 제공하는 웹사이트입니다. 다양한 출처의 공공 데이터를 검색할 수 있습니다. 데이터는 지역과 주제별로 분류됩니다. 예를 들어, 국토교통부 또는 부산광역시의 데이터를 찾을 수 있습니다.
공공데이터포털(https://www.data.go.kr/)
이전에는 공공데이터포털(https://www.data.go.kr/)를 많이 활용하였고 공공데이터를 이용하여 서브포털 만들기와 PWA / App 개발하기를 시도해보았습니다. PWA / App 개발하기는 완성도가 낮아 공개하기에는 부족한 수준입니다.
비공개: 공공데이터를 가지고 PWA / App 개발하기( https://www.seenbuy.kr/%ea%b3%b5%ea%b3%b5%eb%8d%b0%ec%9d%b4%ed%84%b0%eb%a5%bc-%ea%b0%80%ec%a7%80%ea%b3%a0-pwa-app-%ea%b0%9c%eb%b0%9c/ )
참고로 공공데이터포털(https://www.data.go.kr/)는 CKAN으로 만들어졌습니다.
pdf 학술 논문
Google 학술 검색(https://scholar.google.co.kr/schhp?hl=ko) 도 있지만 “키워드 + filetype:pdf”의 형태로 구글 검색 명령어를 주어 검색하는 것이 훨씬 효율적입니다. 많은 무료 데이터베이스( https://www.ncbi.nlm.nih.gov/pmc/, https://arxiv.org/, https://doaj.org/)와 한국 학술 논문 데이터베이스(https://www.kci.go.kr/kciportal/main.kci?locale=en, https://intl.riss.kr/) 등이 있지만 해당 사이트에 들어가 일일히 확인을 한다고 하여도 막상 확보하려면 pdf 파일로 공개되는 정보가 아니라면 확보하기가 어렸습니다.
판례
판례 검색 – 종합법률정보 – 대한민국 법원( https://glaw.scourt.go.kr/wsjo/panre/sjo050.do#1711066445306 )
특허 공고
KIPRIS 특허정보검색서비스( http://www.kipris.or.kr/khome/main.jsp )
기업 공시
전자공시시스템(https://dart.fss.or.kr/) : 금융감독원 전자공시시스템은 상장법인 등이 공시서류를 인터넷으로 제출하고, 이용자는 제출 즉시 인터넷을 통해 공시서류를 조회할 수 있도록 하는 기업공시 시스템이다. 위키백과 저는 개인적인 인연으로 석사 논문을 많이 활용했던 곳이라 이곳을 이하여 우선적으로 AI를 만들어보고자 합니다.
보험 상품 공시
보험상품공시 : 보험료 비교공시 – 손해보험협회( https://kpub.knia.or.kr/productDisc/lostHealth/lostHealthDisclosure.do ), 상품비교공시 안내 – 손해보험협회( https://kpub.knia.or.kr/productDisc/guide/productInf.do )
참과자료 : 1. CKAN을 이용한 공간정보개방 사례 – 프로그웍스 – 티스토리
2. 기미나인은?
{kind=link}
{kind=link}