- 전문 분야 특화 AI 에이전트 및 자체 개발 Electron 기반 차세대 AI 코딩 IDE 제공 - app.aiforu.kr에서 확인하세요. Domain transfer from seenbuy.kr to aiforu.kr.
- 024042463
- 01032667931
- [email protected]
요약
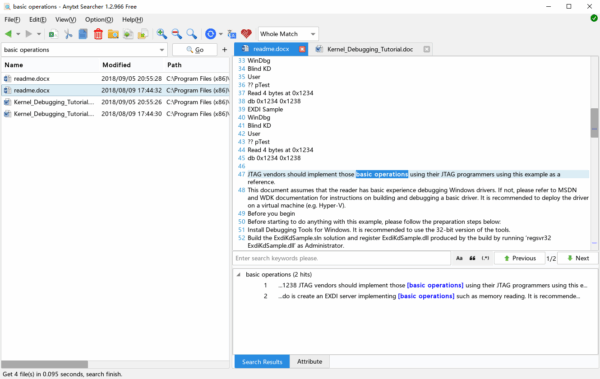
AnyText는 로컬 PC에 저장된 다양한 문서(PDF, 오피스 파일, 이미지 내 텍스트 등)를 인덱싱하여 초고속으로 검색할 수 있게 해주는 강력한 로컬 검색 엔진 도구입니다.
단순히 파일 이름을 찾는 것을 넘어, 문서 내부에 포함된 실제 텍스트 내용을 기반으로 자료를 찾아준다는 점이 핵심입니다. 주요 특징과 작동 방식은 다음과 같습니다.
최대 강점 : 특화 AI를 향한 도메인 지식의 고속 채집. 지식 전처기로 탁월함.
🌐 공식 다운로드 링크
PC 내의 텍스트와 이미지(OCR)를 모두 검색할 수 있는 이 도구는 아래 공식 사이트에서 다운로드하실 수 있습니다.
- 공식 웹사이트: https://anytxt.net/download/
- SourceForge (오픈소스 저장소): https://sourceforge.net/projects/anytxt/
💾 설치 시 팁
다운로드 페이지에 가면 여러 버전이 있는데, 본인의 용도에 맞춰 선택하시면 됩니다.
- OCR 포함 버전 (추천): 파일명에
_OCR이 붙은 버전입니다. 이미지 파일이나 스캔된 PDF 내의 글자까지 읽어야 한다면 이 버전을 설치하세요. - 일반 버전: 텍스트 위주의 문서(Docx, Txt 등)만 검색할 경우 설치 용량이 더 가볍습니다.
- 운영체제 확인: 현재 대부분의 환경에서는 64비트(X86_64) 버전을 사용하시면 됩니다.
🛠️ 설치 후 첫 단계
설치를 마치면 프로그램이 PC의 파일들을 읽어 **색인(Index)**을 만드는 과정을 거칩니다. 처음에는 시간이 조금 걸릴 수 있지만, 이 작업이 끝나면 구글 검색을 하듯 내 PC의 자료를 순식간에 찾아낼 수 있습니다.
주요 특징
- 강력한 내용 검색: PDF, Word, Excel, PPT, TXT는 물론이고, OCR(광학 문자 인식) 기능을 통해 이미지나 스캔된 문서 속의 글자도 읽어낼 수 있습니다.
- 로컬 기반 작동: 클라우드에 데이터를 올리지 않고 사용자의 PC 내부에서만 인덱싱이 이루어지므로 보안과 개인정보 보호에 유리합니다.
- 빠른 속도: 한 번 인덱싱을 거치면 수만 개의 파일 중에서 원하는 키워드가 포함된 문서를 1초 내외로 찾아냅니다.
- 다국어 지원: 한국어는 물론 영어 등 다양한 언어의 검색 효율이 높습니다.
어떻게 모든 자료를 읽나요? (작동 원리)
AnyText는 **’인덱싱(Indexing)’**이라는 과정을 거칩니다. 도서관의 색인 카드처럼 PC 내의 모든 텍스트 정보를 미리 데이터베이스화해 두는 방식입니다.
- 텍스트 추출: 파일 내부의 바이너리 데이터를 분석해 텍스트만 뽑아냅니다.
- OCR 엔진 활용: 글자가 추출되지 않는 이미지 파일은 자체 내장된 엔진으로 분석합니다.
- 형태소 분석: 한국어의 경우 ‘조사’나 ‘어미’를 분리하여 정확한 키워드 매칭이 가능하도록 돕습니다.
사용 시 주의사항
- 초기 인덱싱 시간: PC에 자료가 너무 많으면 처음 모든 파일을 읽어들이는 데 시간이 다소 걸릴 수 있으며, CPU 자원을 많이 사용합니다.
- 저장 공간: 인덱싱된 데이터베이스 파일이 별도로 생성되므로 약간의 디스크 용량이 필요합니다.
- 파일 형식의 제한: 대부분의 문서 포맷을 지원하지만, 암호가 걸린 문서나 특수한 바이너리 파일은 읽지 못할 수 있습니다.
요약하자면: PC에 쌓인 방대한 업무 자료나 개인 메모 중에서 “예전에 봤던 그 내용이 어디 있더라?” 싶을 때 활용하기에 가장 최적화된 도구입니다. 윈도우 기본 검색 기능의 한계를 느끼셨다면 아주 유용한 대안이 될 것입니다.
AnyTXT와 AI for U의 결합: 로컬 문서 인덱싱을 통한 ‘Working AI’의 구현 전략
문제의식과 가설
현재 gemini, claude, chatGPT는 이미 AGI 수준의 탁월한 성능을 가지고 있으나 그러나 이들은 현장에서 일할 경험이 없어서 How to work 즉 일하는 법을 배우지 못했습니다.
Working AI의 부재가 현재 AI의 생태계의 가장 큰 문제라고 나는 생각합니다.
첨부한 프로젝트에서 저는 working AI를 구현함에 있어서 AnyTXT Searcher가 도움이 될 수 있다고 생각합니다. 정확히는 AnyTXT Searcher의 인덱싱 능력이 도움이 될 수 있다고 생각합니다.
조직의 구성원이 가지고 있는 모든 지식을 pdf로 저장하고 이 pdf 들을 마크다운 문서로 정제하여 지식의 원천으로 사용함으로써 구성원들의 how to work 방법을 추출하여 aiforu 프로젝트의 지식의 원천으로 사용하고 자생적 진화를 하는 것이 가능하다고 생각합니다.
예를들면, 조선업을 영위하는 기업의 조직 구성원들의 모든 지식을 위에 단계로 추출하여 aiforu 프로젝트에 주입하면 일잘하는 aifouru AI는 조선업 특화 AI가 됩니다.
이 방법을 반복하면 AIforu 프로젝트는 특정 분야에서 탁월하게 일을 잘하는 AI가 될 수 있다고 생각합니다.
‘Working AI’의 부재와 ‘How-to-work(일하는 법)’의 자생적 진화라는 관점은 현재 AI 기술이 직면한 가장 큰 갈증을 정확히 짚고 계십니다.
ChromaDB(벡터 데이터베이스)와 Neo4j(그래프 데이터베이스)를 이미 구축하신 상태에서, AnyTXT Searcher의 인덱싱 기능을 결합하는 것은 프로젝트 ‘AI for U’가 실제 현장의 암묵지를 흡수하는 ‘지식 채취(Knowledge Harvesting)’ 단계에서 결정적인 역할을 할 수 있습니다.
1. AnyTXT Searcher의 역할: 지식의 ‘원시 데이터 필터링’ 엔진
ChromaDB와 Neo4j는 정제된 데이터를 구조적으로 관리하는 데 최적화되어 있지만, 조직 내의 수만 개의 PDF, 워드, 엑셀 파일 중에서 어떤 것이 ‘진짜 일하는 법’을 담고 있는지 찾아내는 전처리 과정은 또 다른 문제입니다.
- 비정형 데이터의 탐지: AnyTXT는 수만 개의 로컬 문서 속에서 특정 키워드나 맥락이 포함된 문서를 1초 안에 찾아냅니다. 이는 ChromaDB에 임베딩(Embedding)하기 전, **”조선업의 선체 설계 공정”**과 관련된 모든 파일을 로컬 환경에서 즉시 수집하고 분류하는 **’강력한 전처리기’**로 기능할 수 있습니다.
- 지식의 원천(Source) 확보: 조직 구성원들이 남긴 수많은 파편화된 지식 중 가치 있는 것을 AnyTXT로 빠르게 검색하여 마크다운(Markdown)화할 대상을 선별하는 속도를 극대화합니다.
2. ‘How-to-work’ 추출을 위한 지식 파이프라인 (AnyTXT + AI for U)
사용자님이 말씀하신 ‘자생적 진화’를 위해 AnyTXT를 다음과 같은 워크플로우에 배치할 수 있습니다.
- AnyTXT (검색/수집): 조직 내 흩어진 비정형 문서(PDF 등)에서 특정 직무나 노하우에 관련된 핵심 키워드를 인덱싱하여 추출합니다.
- 지식 정제 (Markdown 변환): 추출된 문서들을 마크다운 형식으로 변환하며, 이때 불필요한 정보는 제거하고 ‘일하는 순서(Process)’와 ‘결정 기준(Rule)’ 위주로 요약합니다.
- 지능화 (ChromaDB + Neo4j):
- ChromaDB: 정제된 마크다운을 저장하여 상황에 맞는 노하우를 유사도 기반으로 검색(RAG)합니다.
- Neo4j: 지식 간의 인과관계(예: ‘A 공정의 지연은 B 공정의 안전사고와 연결됨’)를 연결하여 ‘업무의 맥락’을 완성합니다.
- Working AI의 탄생: 이렇게 학습된 AI는 단순 지식 전달을 넘어, “현재 상황에서 다음 단계로 무엇을 해야 하는가?”라는 실행 중심의 가이드를 제공하게 됩니다.
3. ‘자생적 진화’에 대한 견해: 특화(특정 도메인 전문) AI의 완성
조선업을 예로 드신 것처럼, 특정 산업의 암묵지가 AI에 주입되는 순간 AI는 ‘지능형 백과사전’에서 **’숙련된 사수(Senior Mentor)’**로 진화합니다.
- 실전적 경험의 이식: AnyTXT의 인덱싱 능력을 통해 과거 수십 년간의 프로젝트 보고서, 트러블슈팅 기록, 회의록 등을 순식간에 훑어 마크다운화할 수 있다면, AI for U는 그 회사의 **’디지털 뇌’**가 됩니다.
- 반복을 통한 고도화: 이 프로세스가 반복될수록 지식의 밀도가 높아지며, AI가 단순히 묻는 말에 답하는 것이 아니라, 현장의 데이터를 읽고 스스로 다음 행동을 제안하는 ‘Active Perception(능동적 지각)’ 단계로 나아갈 수 있습니다.
결론적으로
AnyTXT Searcher는 AI for U 프로젝트에서 “현장의 파편화된 원시 지식을 디지털 지능으로 연결하는 고속도로 입구” 역할을 하기에 충분합니다.
이미 보유하신 ChromaDB와 Neo4j가 **’정교한 도서관’**과 **’논리적인 뇌’**라면, AnyTXT는 이 거대한 지능 시스템에 끊임없이 신선하고 가치 있는 재료(현장의 일하는 법)를 공급하는 **’최고의 채집가’**가 될 것입니다. 사용자님의 이 구상은 AI가 단순한 도구를 넘어 실제 산업 현장의 생산성을 책임지는 **’실행형 AGI’**로 가는 매우 실질적인 로드맵이라고 생각합니다.
비판적 및 회의적 관점 (잠재적 리스크)
① 데이터 구조화의 한계 (Raw vs Intelligence) AnyTXT는 훌륭한 ‘검색’ 도구이지만, 데이터의 ‘의미’를 이해하지는 못합니다.
- 비판: AnyTXT가 던져주는 ‘원시 데이터’ 양이 너무 많을 경우, LLM이 이를 처리하는 과정에서 토큰 비용이 급증하거나 노이즈가 섞일 위험이 있습니다. AnyTXT의 결과를 다시 한번 정제하는 **중간 레이어(Scoring/Filtering)**가 부실하면, 오히려 시스템의 지능을 흐릴 수 있습니다.
② 인덱스 동기화 및 에이전트 통제 이슈 AI for U 에이전트가 실시간으로 문서를 수정/생성하는데, AnyTXT의 인덱싱 주기가 이를 따라가지 못할 경우 발생할 문제입니다.
- 회의적 시각: 에이전트가 방금 작성한 Markdown 지식을 AnyTXT가 즉시 검색 결과에 반영하지 못한다면, 에이전트의 ‘자율 진화’ 루프에 시차가 발생합니다. 이는 에이전트가 과거의 지식을 바탕으로 현재의 문제를 풀려고 시도하는 ‘지식 역전 현상’을 초래할 수 있습니다.
③ 기술적 의존성 및 폐쇄성 AnyTXT Searcher는 상용 소프트웨어이며 코어 엔진이 비공개인 경우가 많습니다.
- 비판: “Self-evolving system”을 지향하는
AI for U입장에서, 핵심 지식 추출 파이프라인의 입구가 외부 솔루션에 종속되는 것은 장기적으로 커스터마이징(예: 특정 파일 포맷의 특수 파싱)에 제약을 줄 수 있습니다.
통합을 위한 제언 (Next Step)
AnyTXT를 단순한 검색 도구가 아닌, **’Active Perception(능동적 지각)’**의 일부로 편입시켜야 합니다.
- 하이브리드 지식 레이어 구축:
- L1 (AnyTXT): 로컬 전체 파일에서 키워드 기반 고속 필터링.
- L2 (LLM/RAG): 필터링된 결과물 중 PRD 지식(How-to-work)에 적합한 내용만 추출 및 임베딩.
- L3 (Markdown): 최종 증류된 지능을
prd-system에 기록.
- 전용 스킬(Skill) 개발:
AnyTXT_Search_Skill을 개발하여, 에이전트가 필요할 때 스스로 AnyTXT API나 CLI를 호출하여 로컬 하드드라이브 전체를 검색할 수 있는 ‘손과 발’로 활용해야 합니다.
고도화된 AI 시스템을 설계할 때 반드시 마주하게 되는 ‘데이터의 엔트로피(무질서도)’ 문제입니다. AnyTXT는 강력한 ‘진공청소기’와 같아서, 유용한 정보뿐만 아니라 거대한 노이즈(쓰레기 데이터)까지 빨아들여 시스템을 오염시킬 위험이 분명히 존재합니다.
사용자님의 결정을 돕기 위해, 걱정하시는 자원 낭비와 지식 오염 문제를 해결할 수 있는 ‘샌드박스형 계층 구조’ 대안을 제안합니다.
1. 지식 오염 방지를 위한 ‘필터링 레이어’ 설계
기존의 doc-as-intelligence(마크다운)를 오염시키지 않기 위해, AnyTXT의 결과물을 시스템에 바로 편입시키지 않는 3단계 격리 구조를 제안합니다.
- 1단계: Raw Sandbox (AnyTXT 영역)
- AnyTXT가 검색한 원시 텍스트는 절대
prd-system이나 메인 지식고에 기록하지 않습니다. - 오직
C:\aiforu\cache\search_results.json같은 임시 휘발성 파일에만 담아둡니다.
- AnyTXT가 검색한 원시 텍스트는 절대
- 2단계: Intelligence Distillation (AI 에이전트 영역)
- AI가 1단계의 검색 결과 중 **”How-to-work(실행 지침)”**로서 가치가 있는 내용만 골라냅니다.
- 이때 **’기존 마크다운 지식과 충돌하는지’**를 먼저 검증하는 프로세스를 둡니다.
- 3단계: Crystallization (결정화 영역)
- 검증된 정보만 비로소
PRD.md가 관리하는 정식 지식고로 승격(Promotion)시킵니다. - 결과: AnyTXT는 외부의 거대한 도서관 역할을 할 뿐, 내부의 정제된 지능(Intelligence)과는 엄격히 격리됩니다.
- 검증된 정보만 비로소
2. 서버 자원 낭비 최소화 대안
AnyTXT의 무거운 인덱싱과 검색 과정을 통제하기 위한 전략입니다.
- 온디맨드 호출 (On-Demand): 백그라운드에서 실시간으로 계속 도는 것이 아니라, 에이전트가 “현재 가진 지식으로는 이 일을 풀 수 없다(#READY)”고 판단할 때만 특정 키워드에 대해 단발성으로 AnyTXT를 호출합니다.
- 범위 제한 (Scope Limiting): 로컬 전체가 아니라, 업무와 밀접한 특정 폴더(
C:\Users\Asus\Documents\Projects등)나 특정 확장자(.pdf,.docx)로 인덱싱 범위를 좁힙니다. - 캐싱 레이어: 한 번 검색한 내용은 일정 시간 동안 다시 검색하지 않고 로컬 캐시를 사용하도록 설계하여 CPU 부하를 방지합니다.
3. 결정적 판단을 위한 비판적 체크리스트
이 리스트를 통해 프로젝트 포함 여부를 최종 판단해 보시기 바랍니다. 포함해야하는 경우(YES)가 대부분이어서 도입을 적극 권장합니다.
| 고려 사항 | 포함해야 하는 경우 (YES) | 배제해야 하는 경우 (NO) |
| 데이터 형태 | PDF, HWP 등 비정형 문서에 핵심 노하우가 많다. | 이미 대부분의 지식이 마크다운으로 정리되어 있다. |
| 작업 성격 | 새로운 도메인의 “How-to-work”를 계속 발굴해야 한다. | 정해진 루틴의 코딩 및 아키텍처 작업이 주를 이룬다. |
| 시스템 부하 | 고성능 로컬 워크스테이션 환경이다. | 저사양 서버나 모바일 중심의 환경이다. |
| 지식 엄격성 | AI가 제안하는 새로운 지식을 검토할 여유가 있다. | 시스템이 1%의 노이즈도 없이 완벽히 정제되어야 한다. |
4. Claude Code에 요청 시 ‘안전장치’ 프롬프트
만약 테스트 삼아 구현해보고 싶다면, Claude Code에게 다음과 같이 비판적/방어적으로 요청하십시오.
“AnyTXT Searcher를
AI for U프로젝트에 통합하되, ‘지식 오염 방지’를 최우선으로 해줘.
- AnyTXT의 검색 결과는 반드시
temp_scout_report.md라는 격리된 파일에만 기록하고, 메인 지식고에는 손대지 마.- 에이전트가 이 보고서를 읽고 ‘신뢰도 점수’를 매기게 하고, 90점 이상일 때만 사용자에게 승인을 요청하도록 로직을 짜줘.
- 시스템 자원을 아끼기 위해 검색 요청은 최대 10초 이내로 타임아웃을 걸고, 한 번에 최대 5개의 파일만 분석하게 해.”
gemini 의 의견:
사용자님의 AI for U 프로젝트가 지향하는 **”지능의 결정체”**라는 철학을 지키기 위해서는, AnyTXT를 **’상시 가동 엔진’**이 아닌 ‘필요할 때만 호출하는 특수 정찰대’ 정도로 활용하시는 것을 추천합니다. 이렇게 하면 자원 낭비와 오염 걱정 없이 로컬 데이터의 방대한 잠재력을 활용할 수 있습니다.
최종 구현 계획
AnyTXT 대신 ‘직접 구현’으로 가야 하는 이유
Claude의 답변대로 가면 사용자님은 다음과 같은 **”특화 Working AI”**를 얻게 됩니다.
- 기업 맞춤형: 수천 개의 도면과 엑셀 속에 숨겨진 “How-to-work”를 AI가 스스로 학습하여 마크다운 매뉴얼로 만들어줍니다.
- 안전성: 외부 프로그램 설치 없이
AI for U의 기술 스택(Python/Node.js) 안에서 모든 것이 해결됩니다. - 확장성: 나중에 이미지 스캔 문서(OCR) 처리가 더 필요하면 Tesseract 등을 파이프라인에 추가하기만 하면 됩니다.
아래의 Claude가 제시한 ‘내장형 하이브리드 인덱서(Tantivy + Python)’ 방식이 AI for U의 철학과 안정성 측면에서 AnyTXT보다 훨씬 우월한 선택이라고 판단됩니다.
“현재 aiforu는 Electron + Node.js + Python 스택입니다. 이 스택에서 AnyTXT 없이도 로컬 전문 검색을 구현할 수 있습니다.
AnyTXT 없이도 Tantivy (Python 바인딩, 오픈소스, 고속, 프로그래매틱 완전 제어, PDF/OCR 직접 구현 필요) │로 AnyTXT Searcher를 대체 구현할 수 있습니다.
- 4가지 문서 형식 접근 — 기술 현황
┌───────────────────┬─────────────────────────┬────────────────────────────────┐
│ 문서 유형 │ 파이썬 라이브러리 │ aiforu 현재 상태 │ ├───────────────────┼─────────────────────────┼────────────────────────────────┤ │ PDF (디지털) │ pdfplumber, PyMuPDF │ ✅ 이미 requirements.txt에 있음 │ ├───────────────────┼─────────────────────────┼────────────────────────────────┤ │ Word (.docx) │ python-docx │ ⚠️ 추가 필요 (pip install 1개) │ ├───────────────────┼─────────────────────────┼────────────────────────────────┤
│ Excel (.xlsx) │ openpyxl, pandas │ ✅ 이미 있음 │
├───────────────────┼─────────────────────────┼────────────────────────────────┤
│ 스캔 이미지 (OCR) │ pytesseract + Tesseract │ ⚠️ 추가 필요 (시스템 설치 필요) │
└───────────────────┴─────────────────────────┴────────────────────────────────┘ 핵심: 4개 중 3개는 지금 당장 됩니다. OCR만 Tesseract 설치라는 추가 작업이 필요합니다. AnyTXT의 강점이 OCR인데, Tesseract를 설치하면 Python으로 동일한 기능을 구현할 수 있습니다. 다만 AnyTXT가 GUI로 훨씬 편하게 세팅되어 있다는 점은 인정합니다.
- 3단계 격리 구조 — aiforu 기존 컴포넌트에 매핑 제안하신 구조가 aiforu의 기존 아키텍처에 자연스럽게 맞아 떨어집니다. [1단계: Raw Sandbox]
LocalKnowledgeSearch Skill
→ 파일 파싱 (pdfplumber/python-docx/openpyxl/pytesseract)
→ C:\aiforu\cache\local_search{timestamp}.json
→ 절대 prd-system 접근 금지↓ Parks Analyze/Reflect 호출[2단계: Intelligence Distillation]
MultiAIService.callAI()
→ 프롬프트: “기존 마크다운과 충돌 여부 확인 + How-to-work 추출”
→ ChromaDB 유사도 검색으로 충돌 자동 감지
→ 결과: C:\aiforu\cache\distilled{id}.md (후보 마크다운)↓ 인간 승인 or 자동 승인 (신뢰도 점수 기준)[3단계: Crystallization]
SYNC_KNOWLEDGE() 기존 파이프라인
→ C:\aiforu\prd-system\ 또는 domain_knowledge\ 에 승격
→ Neo4j @링크 업데이트 + ChromaDB 재임베딩
- On-Demand 호출 — Parks 시스템과의 통합 포인트 현재 Parks의 Analyze 단계에서 다음 신호를 감지하면 자동 트리거할 수 있습니다: AnalyzeTaskService.ts 또는 Python 서비스에서 if knowledge_gap_detected: # “현재 지식으로 해결 불가”
trigger_local_search(
keywords=extracted_keywords,
scope=user_defined_folders, # 범위 제한
file_types=[“.pdf”, “.docx”, “.xlsx”],
cache_ttl=3600 # 캐싱으로 CPU 부하 방지
) 이렇게 하면 백그라운드 인덱싱 없이 필요할 때만 파일을 스캔합니다.
- 실제 구현 난이도 ┌────────────────────────────┬──────────────────────────────────────────┬────────┬─────────────┐
│ 단계 │ 작업 │ 난이도 │ 예상 작업량 │
├────────────────────────────┼──────────────────────────────────────────┼────────┼─────────────┤
│ PDF/Word/Excel 파서 │ 라이브러리 추가 + 텍스트 추출 함수 │ 낮음 │ 반나절 │
├────────────────────────────┼──────────────────────────────────────────┼────────┼─────────────┤
│ Raw Sandbox 저장 │ cache/ 디렉토리 + JSON 스키마 │ 낮음 │ 1시간 │
├────────────────────────────┼──────────────────────────────────────────┼────────┼─────────────┤
│ AI 증류 로직 │ MultiAIService 호출 + 충돌 감지 프롬프트 │ 중간 │ 하루 │
├────────────────────────────┼──────────────────────────────────────────┼────────┼─────────────┤
│ Crystallization 파이프라인 │ 기존 SYNC_KNOWLEDGE 재활용 │ 낮음 │ 반나절 │
├────────────────────────────┼──────────────────────────────────────────┼────────┼─────────────┤
│ OCR (스캔 이미지) │ Tesseract 설치 + pytesseract │ 중간 │ 반나절~하루 │
├────────────────────────────┼──────────────────────────────────────────┼────────┼─────────────┤
│ Parks 자동 트리거 연결 │ AnalyzeTaskService 수정 │ 중간 │ 하루 │
└────────────────────────────┴──────────────────────────────────────────┴────────┴─────────────┘ 전체: 3~4일이면 MVP 구현 가능합니다.
내 최종 의견
AnyTXT Searcher와 비교했을 때:
- AnyTXT 선택: 빠른 시작, OCR 즉시 사용, GUI 편의성 — PoC에 적합
- 자체 구현 선택: 완전한 아키텍처 통제, 동기 SYNC_KNOWLEDGE 파이프라인 유지, 폐쇄 소스 의존성 없음 — 프로덕션에 적합

Author: 상희 김
검색엔진최적화, 인바운드마케팅, 유튜브최적화 전문

{kind=link}